

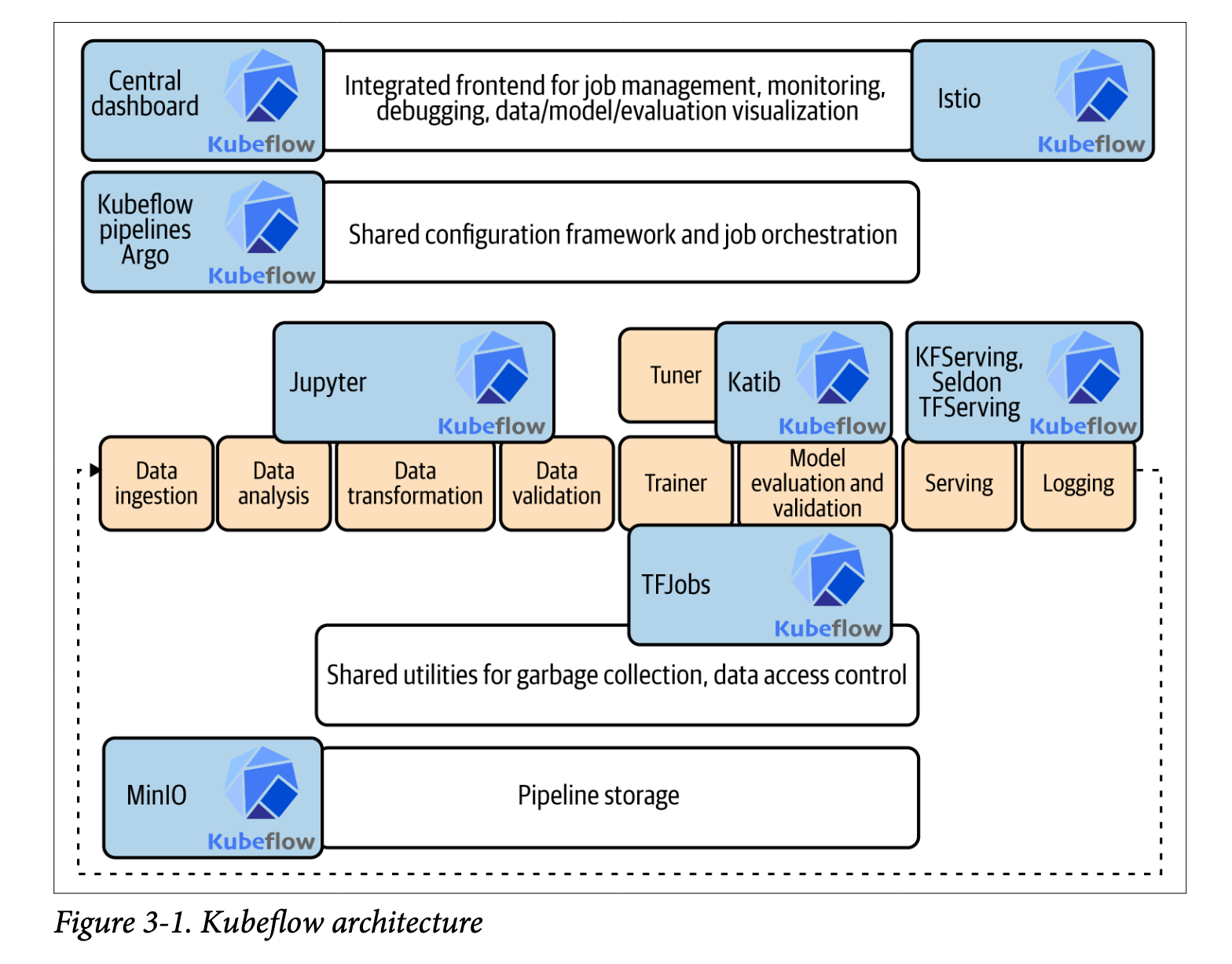
二、Kubeflow架构
1、Notebooks (JupyterHub)
大多数项目的第一步是某种形式的原型和实验。Kubeflow用于此目的的工具是JupyterHub——一个多用户中心,可以生成、管理和代理单用户Jupyter notebook的多个实例。Jupyter notebook支持整个计算过程:开发、记录和执行代码,以及交流结果。
要访问JupyterHub,请转到Kubeflow主页面并单击notebook按钮。在notebook页面上,您可以连接到现有服务器或创建新服务器。
要创建新服务器,您需要指定服务器名称和命名空间,选择镜像(从CPU优化,GPU优化或您可以创建的自定义映像),并指定资源要求-CPU/内存,工作区,数据量,自定义配置等等。创建服务器后,您可以连接到它并开始创建和编辑notebooks.。
为了让数据科学家在不离开notebooks环境的情况下进行集群操作,Kubeflow将kubectl添加到提供的notebooks映像中,允许开发人员使用笔记本创建和管理Kubernetes资源。Jupyter Notebook pod在特殊服务帐户默认编辑器下运行,该帐户对以下Kubernetes资源具有命名空间范围的权限:
Pods
Deployments
Services
Jobs
TFJobs
PyTorchJobs
2、Training Operators
JupyterHub是一个很好的工具,用于数据的初始实验和ML作业的原型。然而,当转移到生产中进行训练时,Kubeflow提供了几个训练组件来自动执行机器学习算法,包括:
Chainer training
MPI training
Apache MXNet training
PyTorch training
TensorFlow training
在Kubeflow中,分布式作业由特定于应用程序的控制器(称为operator)管理。这些operator扩展了Kubernetes API来创建、管理和操作资源的状态。例如,要运行分布式TensorFlow训练作业,用户只需要提供描述所需状态(worker和参数服务器的数量等),TensorFlow operator组件将负责其余工作并管理训练作业的生命周期。
3、Kubeflow Pipelines
除了提供实现特定功能的专用参数外,Kubeflow还具有管道,允许您编排机器学习应用程序的执行。此实现基于Argo Workflows,这是一个用于Kubernetes的开源容器原生工作流引擎。Kubeflow安装所有Argo组件。
在高层次上,流水线的执行包含以下组件:
Python SDK:您可以使用Kubeflow Pipelines DSL创建组件或指定管道。
DSL compiler:DSL编译器将管道的Python代码转换为静态配置(YAML)。
Pipeline Service:Pipeline Service从静态配置创建管道运行
Kubernetes resources:Pipeline Service调用Kubernetes API server来创建必要的Kubernetes自定义资源定义(CRD)来运行管道。
Orchestration controllers:一组编排控制器执行完成Kubernetes资源(CRD)指定的管道执行所需的容器。容器在虚拟机上的Kubernetes pod中执行。一个示例控制器是Argo工作流控制器,它编排任务驱动的工作流。
Artifact storage
Kubernetes Pod存储两种数据:
Metadata:实验、作业、运行、单个标量指标(通常出于排序和过滤的目的而聚合)等。Kubeflow Pipelines将元数据存储在MySQL数据库中。
Artifacts:管道包、视图、时间序列等大规模指标(通常用于调查单个运行的性能和调试)等。Kubeflow Pipelines将工件存储在MinIO server、Google Cloud Storage(GCS)或Amazon S3等工件存储中。
Kubeflow Pipelines使您能够使您的机器学习作业可重复并处理新数据。它用Python提供了一个直观的DSL来编写管道。然后,您的管道被编译到现有的Kubernetes工作流引擎(目前是Argo工作流)。Kubeflow的管道组件可以轻松使用和协调构建端到端机器学习项目所需的不同工具。最重要的是,Kubeflow可以跟踪数据和元数据,改善我们对工作的理解。
4、Hyperparameter Tuning
为您的训练模型找到一组正确的超参数可能是一项具有挑战性的任务。网格搜索等传统方法可能非常耗时且乏味。大多数现有的超参数系统都绑定到一个机器学习框架上,并且只有几个选项来搜索参数空间。
Kubeflow提供了一个组件(称为Katib),允许用户在Kubernetes集群上轻松执行超参数优化。Katib支持超参数调优,可以与任何深度学习框架一起运行,包括TensorFlow、MXNet和PyTorch。
Katib基于四个主要概念:
Experiment:在可行空间上运行单个优化。每个实验都包含一个描述可行空间的配置,以及一组试验。假设目标函数f(x)在实验过程中不改变。
Trial:参数值x的列表,将导致f(x)的单个计算。试验可以“完成”,这意味着它已经被评估并且目标值f(x)已被分配给它,否则它是“待定”。一次审判对应一份工作。
Job:负责评估未决审判并计算其目标值的过程。
Suggestion:构造参数集的算法。目前,Katib支持以下探索算法:Random、Grid、Hyperband、Bayesian optimization。
5、Model Inference
Kubeflow可以轻松地在生产环境中大规模部署机器学习模型。它提供了几个模型服务选项,包括TFServing、Seldon serving、PyTorch serving和TensorRT。它还提供了一个伞式实现KFServing,它概括了自动扩展、网络、健康检查和服务器配置的模型推理关注点。
6、Metadata
除了直接支持ML操作的组件外,Kubeflow还提供了几个支持组件。
Kubeflow的一个重要组件是元数据管理,提供捕获和跟踪有关模型创建的信息的功能。许多组织每天构建数百个模型,但很难管理模型的所有相关信息。ML元数据既是基础设施,也是用于记录和检索与ML开发人员和数据科学家工作流相关联的元数据的库。可以在元数据组件中注册的信息包括:
用于创建模型的数据源
通过管道的组件/步骤生成的artifacts
这些组件/步骤的执行
7、MinIO
流水线架构的基础是共享存储。如今,一种常见的做法是将数据保存在外部存储中。不同的云提供商有不同的解决方案,如亚马逊S3、Azure数据存储、谷歌云存储等。解决方案的多样性使得将解决方案从一个云提供商移植到另一个云提供商变得复杂。为了最大限度地减少这种依赖性,Kubeflow附带了MinIO,这是一款高性能分布式对象存储服务器,专为大规模私有云基础设施而设计。不仅仅是私有云,MinIO还可以充当公共API的一致网关。
MinIO可以部署在几种不同的配置中。当MinIO在一个容器上使用Kubernetes内置持久存储运行时,Kubeflow的默认模式是单个容器模式。分布式MinIO允许您将多个volumes到单个对象存储服务中。
虽然Kubeflow的默认MinIO设置有效,但您可能需要进一步配置它。Kubeflow同时安装MinIO服务器和UI。您可以访问MinIO UI并探索存储的内容,
8、Knative
Kubeflow使用的另一个看不见的支持组件是Knative。我们将从描述最重要的部分开始:Knative服务。Knative Serving基于Kubernetes和Istio构建,支持无服务器应用程序的部署和服务。Knative Serving项目提供了中间件原语,这些原语支持:
快速部署无服务器容器
自动放大和缩小到零
Istio组件的路由和网络编程
已部署代码和配置的时间点快照
Knative服务被实现为一组Kubernetes CRD。这些对象用于定义和控制无服务器工作负载的行为:
service
route
configuration
revision
9、Apache Spark
Kubeflow中一个更明显的支持组件是Apache Spark。从Kubeflow 1.0开始,Kubeflow有一个内置的Spark operator来运行Spark作业。
Apache Spark允许您处理单个机器无法处理的更大数据集和规模问题。虽然Spark确实有自己的机器学习库,但它更常用作机器学习管道的一部分,用于数据或特征准备。

