

一、KubeFlow概述
参考书籍:《Kubeflow for Machine Learning From Lab to Production》
模型开发生命周期(Model development life cycle)(MDLC)是一个通常用于描述训练和推理之间的流程的术语。在触发模型更新时,整个循环再次开始。
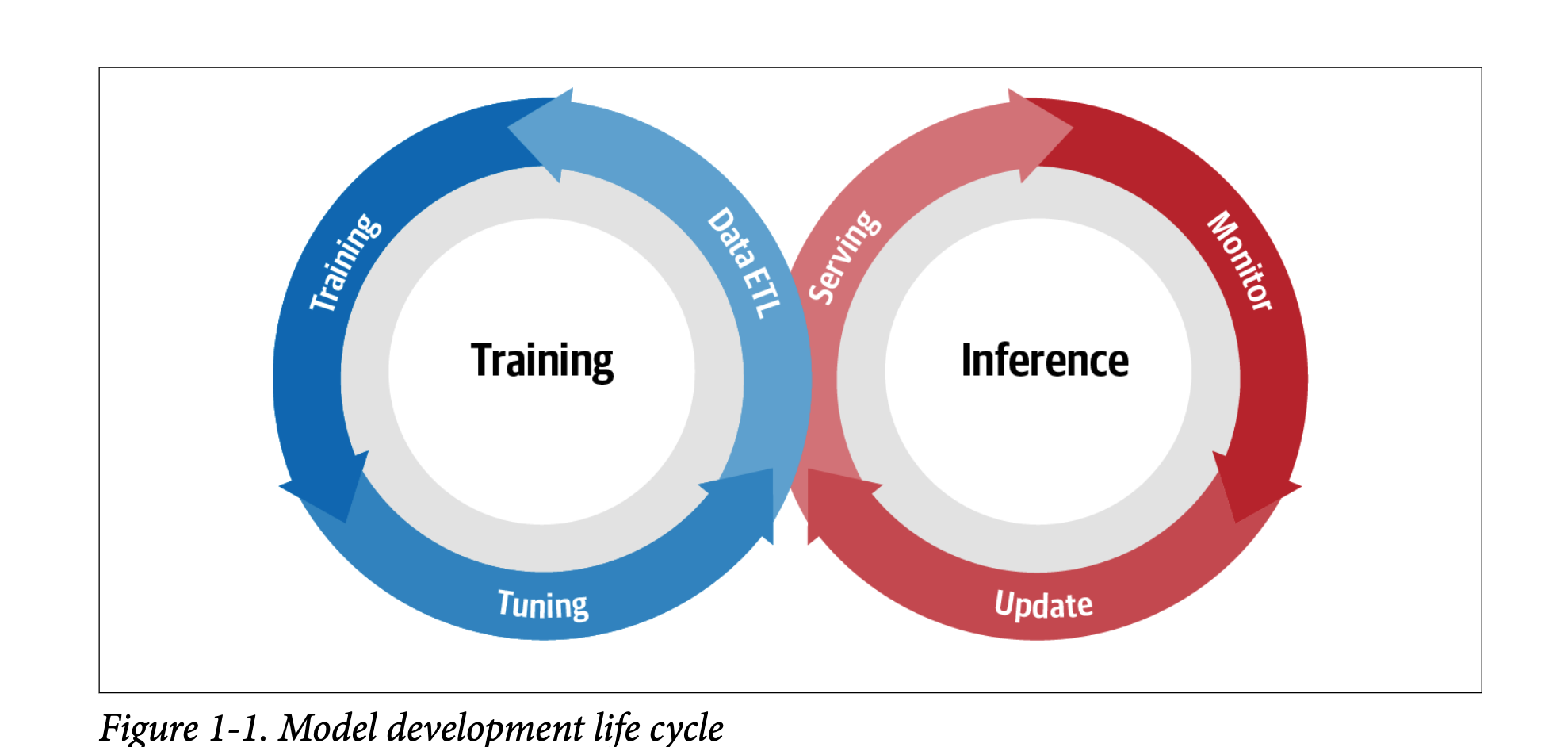
Kubeflow是用于MDLC所有阶段(数据探索、功能准备、模型训练/调优、模型服务、模型测试和模型版本控制)的云原生工具的集合。Kubeflow还拥有允许这些传统上独立的工具无缝协同工作的工具。该工具的一个重要部分是管道系统,它允许用户构建集成的端到端管道来连接其MDLC的所有组件。
Kubeflow面向希望构建生产级机器学习实现的数据科学家和数据工程师。Kubeflow可以在本地开发环境中运行,也可以在生产集群上运行。通常,管道将在本地开发,并在管道准备就绪后进行迁移。Kubeflow提供了一个统一的系统——利用Kubernetes实现容器化和可扩展性,实现其管道的可移植性和可重复性。
Kubeflow试图通过三个特性来解决简化机器学习的问题:可组合性、可移植性和可扩展性。
可组合:Kubeflow的核心组件来自机器学习从业者已经熟悉的数据科学工具。它们可以独立使用以促进机器学习的特定阶段,也可以组合在一起形成端到端管道。
可移植:通过基于容器的设计并利用Kubernetes及其云原生架构,Kubeflow不需要您锚定到任何特定的开发人员环境。您可以在笔记本电脑上进行实验和原型制作,并毫不费力地部署到生产环境中。
可扩展:通过使用Kubernetes,Kubeflow可以根据集群上的需求,通过更改底层容器和机器的数量和大小来动态扩展。
让我们快速浏览一下Kubeflow的一些组件以及它们如何支持这些功能。
1、使用Notebooks进行数据探索
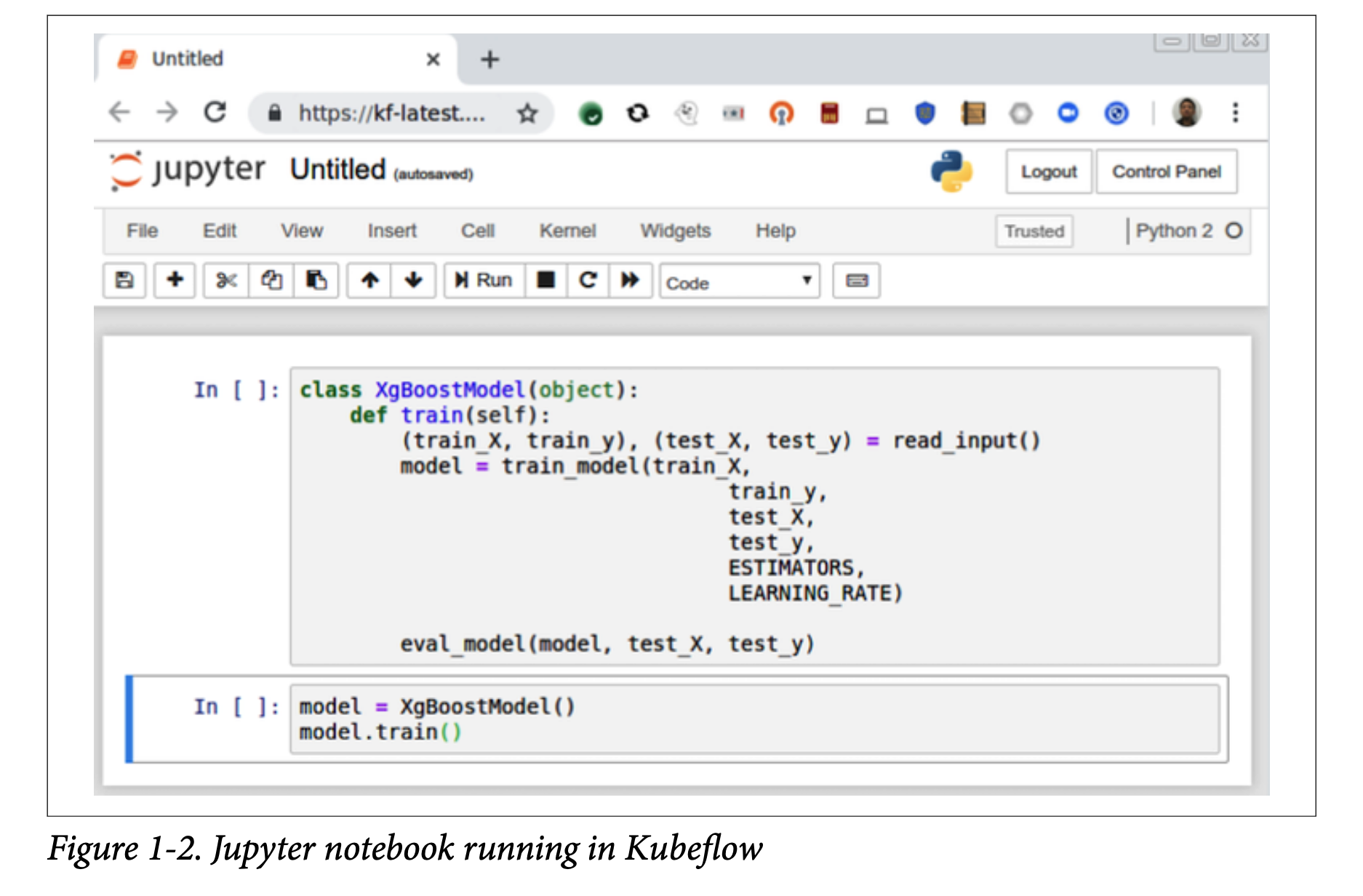
MDLC始终从数据探索开始-绘制,分段和操作您的数据,以了解可能存在的洞察力。为这种数据探索提供工具和环境的一个强大工具是Jupyter。Jupyter是一个开源的web应用程序,允许用户创建和共享数据、代码片段和实验。Jupyter因其简单性和可移植性而受到机器学习从业者的欢迎。
在Kubeflow中,您可以启动直接与集群及其其他组件交互的Jupyter实例,如图1-2所示。例如,您可以在笔记本电脑上编写TensorFlow分布式训练代码片段,只需点击几下就可以调出一个训练集群。
2、数据/特征准备
机器学习算法需要好的数据才能有效,通常需要特殊的工具来有效地提取、转换和加载数据。人们通常过滤,归一化和准备输入数据,以便从非结构化,嘈杂的数据中提取有见地的特征。Kubeflow为此支持几种不同的工具:
Apache Spark(最流行的大数据工具之一)
TensorFlow Transform(与TensorFlow集成,便于推理)
这些不同的数据准备组件可以处理各种格式和数据大小,旨在与您的数据探索环境很好地配合使用。
3、训练
一旦你的特性准备好了,你就可以构建和训练你的模型了。Kubeflow支持多种分布式训练框架。截至撰写本文时,Kubeflow支持:
TensorFlow
PyTorch
Apache MXNet
XGBoost
Chainer
Caffe2
Message passing interface (MPI)
4、超参数调优
你如何优化你的模型架构和训练?在机器学习中,超参数是控制训练过程的变量。例如,模型的学习率应该是多少?神经网络中应该有多少个隐藏层和神经元?这些参数不是训练数据的一部分,但它们可以对训练模型的性能产生显著影响。
使用Kubeflow,用户可以从他们不确定的训练模型开始,定义超参数搜索空间,Kubeflow将使用不同的超参数处理剩余的旋转训练作业,收集指标并将结果保存到模型数据库,以便可以比较它们的性能。
5、模型验证
在将模型投入生产之前,了解它的表现非常重要。用于超参数调整的相同工具可以为模型验证执行交叉验证。当您更新现有模型时,可以在模型推理中使用A/B测试等技术来在线验证您的模型。
6、推理/预测
训练完模型后,下一步是在集群中为模型提供服务,以便它可以处理预测请求。Kubeflow使数据科学家可以轻松地在生产环境中大规模部署机器学习模型。目前,除了TensorFlow Serving和Seldon Core等现有解决方案之外,Kubeflow还为模型服务(KFServing)提供了一个多框架组件。
7、Pipelines
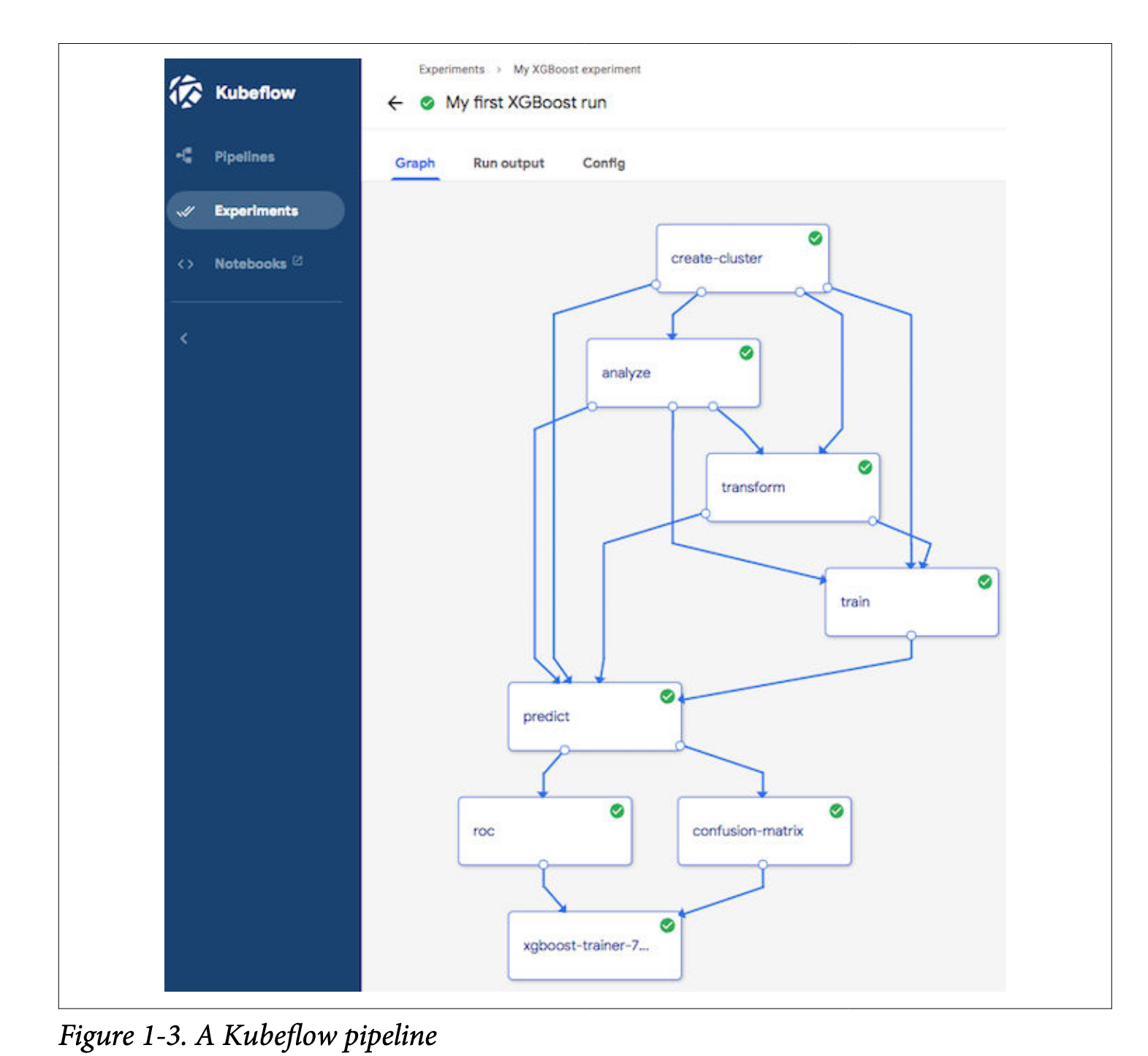
现在我们已经完成了MDLC的所有方面,我们希望实现这些实验的可重用性和治理。为此,Kubeflow将MDLC视为一个机器学习管道,并将其实现为一个图,其中每个节点都是工作流中的一个阶段,如图1-3所示。Kubeflow Pipelines是一个允许用户轻松编写可重用工作流的组件。其特点包括:
用于多步骤工作流的编排引擎
与管道组件交互的SDK
允许用户可视化和跟踪实验并与合作者共享结果的用户界面
8、MNIST
在ML中,Modified National Institute of Standards and Technology (MNIST)通常指用于分类的手写数字数据集。数字相对较小的数据大小,以及它作为示例的常见用途,允许我们探索各种工具。在某些方面,MNIST已经成为机器学习的标准“hello world”示例之一。

