

NVIDIA GPU & K8s
参考:https://www.cnblogs.com/KubeExplorer/p/18624112
NVIDIA 实现了NVIDIA/k8s-device-plugin 来使得节点上的 GPU 能够被 k8s 感知到。具体的device plugin可以看http://www.wuyq.net/archives/k8s-device-plugin。
这个 device plugin 主要做两件事:
1)检测节点上的 GPU 设备并上报给 Kubelet,再由 Kubelet 更新节点信息时提交到 kube-apiserver。
这样 k8s 就知道每个节点上有多少 GPU 了,后续 Pod 申请 GPU 时就会往有 GPU 资源的节点上调度。
2)Pod 申请 GPU 时,为对应容器添加一个NVIDIA_VISIBLE_DEVICES环境变量,后续底层 Runtime 在真正创建容器时就能根据这些信息把 GPU 挂载到容器中
例如添加环境变量: NVIDIA_VISIBLE_DEVICES=GPU-03f69c50-207a-2038-9b45-23cac89cb67d
1、GPU如何分配给Pod
NVIDIA 提供了 nvidia-container-toolkit 来处理如何将 GPU 分配给容器的问题。
核心组件有以下三个:
nvidia-container-runtime
nvidia-container-runtime-hook
nvidia-container-cli
首先需要将 docker/containerd 的 runtime 设置为nvidia-container-runtime,此后整个调用链就变成这样了:
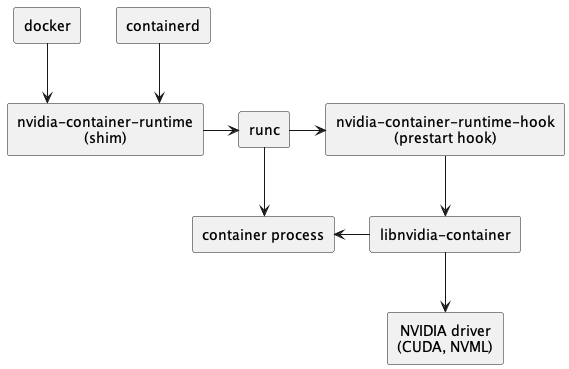
接下来就具体分析每个组件的作用。
(1)nvidia-container-runtime
nvidia-container-runtime 的作用就是负责在容器启动之前,将 nvidia-container-runtime-hook 注入到 prestart hook。
小知识:docker/containerd 都是高级 Runtime,runC 则是低级 Runtime。不同层级 Runtime 通过 OCI Spec 进行交互。
也就是说 docker 调用 runC 创建容器时,会把 docker 收到的信息解析,组装成 OCI Spec,然后在往下传递。
而 nvidia-container-runtime 的作用就是修改容器 Spec,往里面添加一个 prestart hook,这个 hook 就是 nvidia-container-runtime-hook 。
这样 runC 根据 Spec 启动容器时就会执行该 hook,即执行 nvidia-container-runtime-hook。
也就是说 nvidia-container-runtime 其实没有任何逻辑,真正的逻辑都在 nvidia-container-runtime-hook 中。
(2)nvidia-container-runtime-hook
nvidia-container-runtime-hook 包含了给容器分配 GPU 的核心逻辑,主要分为两部分:
1)从容器 Spec 的 mounts 和 env 中解析 GPU 信息
mounts 对应前面 device plugin 中设置的 Mount 和 Device,env 则对应 Env
2)调用 nvidia-container-cli configure 命令,保证容器内可以使用被指定的 GPU 以及对应能力
也就是说nvidia-container-runtime-hook 最终还是调用 nvidia-container-cli 来实现的给容器分配 GPU 能力的。
(3)nvidia-container-cli
nvidia-container-cli 是一个命令行工具,用于配置 Linux 容器对 GPU 硬件的使用。
提供了三个命令
list: 打印 nvidia 驱动库及路径
info: 打印所有Nvidia GPU设备
configure: 进入给定进程的命名空间,执行必要操作保证容器内可以使用被指定的 GPU 以及对应能力(指定 NVIDIA 驱动库)
一般主要使用 configure 命令,它将 NVIDIA GPU Driver、CUDA Driver 等 驱动库的 so 文件 和 GPU 设备信息, 通过文件挂载的方式映射到容器中。
整个流程如下:
1)device plugin 上报节点上的 GPU 信息
2)用户创建 Pod,在 resources.rquest 中申请 GPU,Scheduler 根据各节点 GPU 资源情况,将 Pod 调度到一个有足够 GPU 的节点
3)DevicePlugin 根据 Pod 中申请的 GPU 资源,为容器添加 Env 和 Devices 配置
例如添加环境变量:
NVIDIA_VISIBLE_DEVICES=GPU-03f69c50-207a-2038-9b45-23cac89cb67d
4)docker / containerd 启动容器
由于配置了 nvidia-container-runtime,因此会使用 nvidia-container-runtime 来创建容器
nvidia-container-runtime 额外做了一件事:将
nvidia-container-runtime-hook作为 prestart hook 添加到容器 spec 中,然后就将容器 spec 信息往后传给 runC 了。runC 创建容器前会调用 prestart hook,其中就包括了上一步添加的 nvidia-container-runtime-hook,该 hook 主要做两件事:
从容器 Spec 的 mounts 或者 env 中解析 GPU 信息
调用
nvidia-container-cli configure命令,将 NVIDIA 的 GPU Driver、CUDA Driver 等库文件挂载进容器,保证容器内可以使用被指定的 GPU以及对应能力
以上就是在 k8s 中使用 NVIDIA GPU 的流程,简单来说就是:
1)device plugin 中根据 pod 申请的 GPU 资源分配 GPU,并以 ENV 环境变量方式添加到容器上。
2)nvidia-container-toolkit 则根据该 Env 拿到要分配给该容器的 GPU 最终把相关文件挂载到容器里
2、nvidia-container-toolkit 源码分析
这部分我们主要分析,为什么添加了NVIDIA_VISIBLE_DEVICES 环境变量就会给该容器分配 GPU,nvidia-container-toolkit 中做了哪些处理。
nvidia-container-toolkit 包含以下 3 个部分:
nvidia-container-runtime
nvidia-container-runtime-hook
nvidia-container-cli
2.1、nvidia-container-runtime
nvidia-container-runtime 可以看做是一个 docker/containerd 的底层 runtime(类似 runC),在模块在创建容器的整个调用链中处在如下位置:
它只做一件事,就是在容器启动之前,将 nvidia-container-runtime-hook 注入到 prestart hook。
以修改容器 Spec 的方式添加一个 prestart hook 进去
这样,后续 runC 使用容器 Spec 创建容器时就会执行该 prestart hook。
path := m.nvidiaContainerRuntimeHookPath
spec.Hooks.Prestart = append(spec.Hooks.Prestart, specs.Hook{
Path: path,
Args: append(args, "prestart"),
})可以看到,最终就是添加了一个 prestart hook,hook 的 path 就是 nvidia-container-runtime-hook 这个二进制文件的位置。
至此,nvidia-container-runtime 的工作就完成了,容器真正启动时,底层 runtime(比如 runC)检测到容器的 Spec 中有这个 hook 就会去执行了,最终 nvidia-container-runtime-hook 就会被运行了。
2.2、nvidia-container-runtime-hook
该组件则是 nvidia-container-toolkit 中的核心,所有的逻辑都在这里面实现。
主要做两件事:
1)从容器的 env 中解析 GPU 信息
2)调用 nvidia-container-cli configure 命令,挂载相关文件,保证容器内可以使用被指定的GPU以及对应能力
也是先从启动命令看起:nvidia-container-runtime-hook/main.go
switch args[0] {
case "prestart":
doPrestart()
os.Exit(0)
case "poststart":
fallthrough
case "poststop":
os.Exit(0)
default:
flag.Usage()
os.Exit(2)
}我们是添加的 prestart hook,因此会走 prestart 分支 执行doPrestart()方法。
args := []string{getCLIPath(cli)}
container := getContainerConfig(*hook)
err = syscall.Exec(args[0], args, env)一个是 getContainerConfig 解析容器配置 ,另一个就是 exec 真正开始执行命令。
getContainerConfig 这部分就是解析 Env 拿到要分配给该容器的 GPU,如果没有 NVIDIA_VISIBLE_DEVICES 环境变量就不会做任何事情。
func getContainerConfig(hook HookConfig) (config containerConfig) {
var h HookState
d := json.NewDecoder(os.Stdin)
if err := d.Decode(&h); err != nil {
log.Panicln("could not decode container state:", err)
}
b := h.Bundle
if len(b) == 0 {
b = h.BundlePath
}
s := loadSpec(path.Join(b, "config.json"))
image, err := image.New(
image.WithEnv(s.Process.Env),
image.WithDisableRequire(hook.DisableRequire),
)
if err != nil {
log.Panicln(err)
}
privileged := isPrivileged(s)
return containerConfig{
Pid: h.Pid,
Rootfs: s.Root.Path,
Image: image,
Nvidia: getNvidiaConfig(&hook, image, s.Mounts, privileged),
}
}
构建了一个 image 对象,注意这里把 ENV 也传进去了。之前说了需要给容器分配什么 GPU 是通过 NVIDIA_VISIBLE_DEVICES 环境变量指定的。
image, err := image.New(
image.WithEnv(s.Process.Env),
image.WithDisableRequire(hook.DisableRequire),
)然后解析配置:
func getNvidiaConfig(hookConfig *HookConfig, image image.CUDA, mounts []Mount, privileged bool) *nvidiaConfig {
legacyImage := image.IsLegacy()
var devices string
if d := getDevices(hookConfig, image, mounts, privileged); d != nil {
devices = *d
} else {
// 'nil' devices means this is not a GPU container.
return nil
}
var migConfigDevices string
if d := getMigConfigDevices(image); d != nil {
migConfigDevices = *d
}
if !privileged && migConfigDevices != "" {
log.Panicln("cannot set MIG_CONFIG_DEVICES in non privileged container")
}
var migMonitorDevices string
if d := getMigMonitorDevices(image); d != nil {
migMonitorDevices = *d
}
if !privileged && migMonitorDevices != "" {
log.Panicln("cannot set MIG_MONITOR_DEVICES in non privileged container")
}
var imexChannels string
if c := getImexChannels(image); c != nil {
imexChannels = *c
}
driverCapabilities := hookConfig.getDriverCapabilities(image, legacyImage).String()
requirements, err := image.GetRequirements()
if err != nil {
log.Panicln("failed to get requirements", err)
}
return &nvidiaConfig{
Devices: devices,
MigConfigDevices: migConfigDevices,
MigMonitorDevices: migMonitorDevices,
ImexChannels: imexChannels,
DriverCapabilities: driverCapabilities,
Requirements: requirements,
}
}
核心是 getDevice,就是根据 Mounts 信息或者 Env 解析要分配给该容器的 GPU
func getDevices(hookConfig *HookConfig, image image.CUDA, mounts []Mount, privileged bool) *string {
// If enabled, try and get the device list from volume mounts first
if hookConfig.AcceptDeviceListAsVolumeMounts {
devices := getDevicesFromMounts(mounts)
if devices != nil {
return devices
}
}
// Fallback to reading from the environment variable if privileges are correct
devices := getDevicesFromEnvvar(image, hookConfig.getSwarmResourceEnvvars())
if devices == nil {
return nil
}
if privileged || hookConfig.AcceptEnvvarUnprivileged {
return devices
}
configName := hookConfig.getConfigOption("AcceptEnvvarUnprivileged")
log.Printf("Ignoring devices specified in NVIDIA_VISIBLE_DEVICES (privileged=%v, %v=%v) ", privileged, configName, hookConfig.AcceptEnvvarUnprivileged)
return nil
}
可以看到这里根据配置不同,提供了两种解析 devices 的方法:
getDevicesFromMounts
getDevicesFromEnvvar
这也就是为什么 nvidia device plugin 除了实现 Env 之外还实现了另外的方式,二者配置应该要对应才行。
这里我们只关注 getDevicesFromEnvvar,从环境变量里解析 Device:
envNVVisibleDevices = "NVIDIA_VISIBLE_DEVICES"
func getDevicesFromEnvvar(image image.CUDA, swarmResourceEnvvars []string) *string {
// We check if the image has at least one of the Swarm resource envvars defined and use this
// if specified.
var hasSwarmEnvvar bool
for _, envvar := range swarmResourceEnvvars {
if image.HasEnvvar(envvar) {
hasSwarmEnvvar = true
break
}
}
var devices []string
if hasSwarmEnvvar {
devices = image.DevicesFromEnvvars(swarmResourceEnvvars...).List()
} else {
devices = image.DevicesFromEnvvars(envNVVisibleDevices).List()
}
if len(devices) == 0 {
return nil
}
devicesString := strings.Join(devices, ",")
return &devicesString
}
核心如下:
devices = image.DevicesFromEnvvars(envNVVisibleDevices).List()从 image 里面提取NVIDIA_VISIBLE_DEVICES环境变量,至于这个 Env 是哪里来的,也是容器 Spec 中定义的,之前 image 是这样初始化的:
s := loadSpec(path.Join(b, "config.json"))
image, err := image.New(
image.WithEnv(s.Process.Env), // 这里把容器 env 传给了 image 对象
image.WithDisableRequire(hook.DisableRequire),
)至此,我们知道了这边 runtime 是怎么指定要把哪些 GPU 分配给容器了,接下来进入 Exec 逻辑。
Exec 部分比较短,就是这两行代码:
args := []string{getCLIPath(cli)}
err = syscall.Exec(args[0], args, env)首先是 getCLIPath,用于寻找 nvidia-container-cli 工具的位置并作为第一个参数。
最后则是调用 syscall.Exec 真正开始执行命令
该命令具体在做什么呢,接着分析 nvidia-container-cli 实现。
2.3、nvidia-container-cli
nvidia-container-cli 是一个 C 写的小工具,主要作用就是根据上执行命令时传递的参数,把GPU 设备及其相关依赖库挂载到容器中,使得容器能够正常使用 GPU 能力。
简单看下部分代码。
首先是驱动信息:
// https://github.com/NVIDIA/libnvidia-container/blob/master/src/cli/configure.c#L279-L288
/* Query the driver and device information. */
if (perm_set_capabilities(&err, CAP_EFFECTIVE, ecaps[NVC_INFO], ecaps_size(NVC_INFO)) < 0) {
warnx("permission error: %s", err.msg);
goto fail;
}
if ((drv = libnvc.driver_info_new(nvc, NULL)) == NULL ||
(dev = libnvc.device_info_new(nvc, NULL)) == NULL) {
warnx("detection error: %s", libnvc.error(nvc));
goto fail;
}
nvc_driver_info_new():获取 CUDA Driver 信息nvc_device_info_new():获取 GPU Drvier 信息
然后获取容器中可见的 GPU 列表
// https://github.com/NVIDIA/libnvidia-container/blob/master/src/cli/configure.c#L308-L314
/* Select the visible GPU devices. */
if (dev->ngpus > 0) {
if (select_devices(&err, ctx->devices, dev, &devices) < 0) {
warnx("device error: %s", err.msg);
goto fail;
}
}
最后则是将相关驱动挂载到容器里去:
// https://github.com/NVIDIA/libnvidia-container/blob/master/src/cli/configure.c#L362-L408
/* Mount the driver, visible devices, mig-configs and mig-monitors. */
if (perm_set_capabilities(&err, CAP_EFFECTIVE, ecaps[NVC_MOUNT], ecaps_size(NVC_MOUNT)) < 0) {
warnx("permission error: %s", err.msg);
goto fail;
}
if (libnvc.driver_mount(nvc, cnt, drv) < 0) {
warnx("mount error: %s", libnvc.error(nvc));
goto fail;
}
for (size_t i = 0; i < devices.ngpus; ++i) {
if (libnvc.device_mount(nvc, cnt, devices.gpus[i]) < 0) {
warnx("mount error: %s", libnvc.error(nvc));
goto fail;
}
}
libnvidia-container是采用 linux c mount --bind功能将 CUDA Driver Libraries/Binaries一个个挂载到容器里,而不是将整个目录挂载到容器中。
可通过NVIDIA_DRIVER_CAPABILITIES环境变量指定要挂载的 driver libraries/binaries。
例如:
docker run -e NVIDIA_VISIBLE_DEVICES=0,1 -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -it tensorflow/tensorflow:latest-gpu bash
指定NVIDIA_DRIVER_CAPABILITIES=compute,utility 就会把 compute 和 utility 相关的库挂载进去。
这样容器里就可以使用 GPU 了。
至此,相关源码就分析完成了。
3、总结
整个流程如下:
1)device plugin (list and watch)上报节点上的 GPU 信息
2)用户创建 Pod,在 resources.rquest 中申请 GPU,Scheduler 根据各节点 GPU 资源情况,将 Pod 调度到一个有足够 GPU 的节点
3)DevicePlugin (allocate)根据 Pod 中申请的 GPU 资源,为容器添加
NVIDIA_VISIBLE_DEVICES环境变量例如:
NVIDIA_VISIBLE_DEVICES=GPU-03f69c50-207a-2038-9b45-23cac89cb67d
4)docker / containerd 启动容器
由于配置了 nvidia-container-runtime,因此会使用 nvidia-container-runtime 来创建容器
nvidia-container-runtime 额外做了一件事:将
nvidia-container-runtime-hook作为 prestart hook 添加到容器 spec 中,然后就将容器 spec 信息往后传给 runC 了。runC 创建容器前会调用 prestart hook,其中就包括了上一步添加的 nvidia-container-runtime-hook,该 hook 主要做两件事:
从容器 Spec 的 mounts 或者 env 中解析 GPU 信息
调用
nvidia-container-cli命令,将 NVIDIA 的 GPU Driver、CUDA Driver 等库文件挂载进容器,保证容器内可以使用被指定的 GPU以及对应能力
核心就是两个部分:
device plugin 根据 GPU 资源申请为容器添加
NVIDIA_VISIBLE_DEVICES环境变量nvidia-container-toolkit 则是根据
NVIDIA_VISIBLE_DEVICES环境变量将 GPU、驱动等相关文件挂载到容器里。
GPT:Pod 之所以“能用到 GPU”,是因为运行时只把被允许的 /dev/nvidia* 设备节点和驱动/库挂进容器,并用 cgroup 设备权限 + CUDA 的可见性过滤把其它 GPU 全部屏蔽。容器里跑的进程(PyTorch、TensorFlow、FFmpeg、NVENC 等)通过 libcuda.so 打开这些字符设备,向宿主机内核驱动发 ioctl 调用,最终把工作交给对应的那块 GPU。
Device Plugin 负责“分配哪块”的决策 + 标记(env/mount/devices)。
nvidia-container-runtime 负责把 那块 GPU 的设备节点和驱动库 挂进容器并设好 cgroup 权限。
应用仅仅按正常的 CUDA 用法编程(cudaSetDevice()、torch.cuda.*),剩下的由 驱动与运行时 完成——因此 Pod 就“自然地用上”了被分配的那块 GPU,同时被硬性隔离在那块以内。

