

三、Kubeflow Pipelines
在上一章中,我们描述了Kubeflow管道,它是Kubeflow中用于编排ML程序的组件。编排是必要的,因为典型的机器学习实现使用工具的组合来准备数据、训练模型、评估性能和部署。通过在代码中形式化步骤及其排序,管道允许用户正式捕获所有数据处理步骤,确保它们的可再现性和可审计性,以及培训和部署步骤。
我们将从Pipelines UI开始本章,并展示如何开始用Python编写简单的Pipelines。我们将探索如何在阶段之间传输数据,然后继续研究如何利用现有应用程序作为管道的一部分。我们还将研究底层工作流引擎-Argo Workflows,一个标准的Kubernetes管道工具-Kubeflow使用它来运行管道。了解Argo工作流的基础知识可以让您更深入地了解Kubeflow管道,并有助于调试。然后,我们将展示Kubeflow Pipelines为Argo增加了什么。
Kubeflow Pipelines平台包括:
用于管理和跟踪管道及其执行的UI
用于调度流水线执行的引擎
用于在Python中定义、构建和部署管道的SDK
Notebook支持使用SDK和管道执行
1、Pipelines UI
为了帮助用户理解管道,Kubeflow安装了一些示例管道:

单击一个特定的管道将显示其执行图或源:
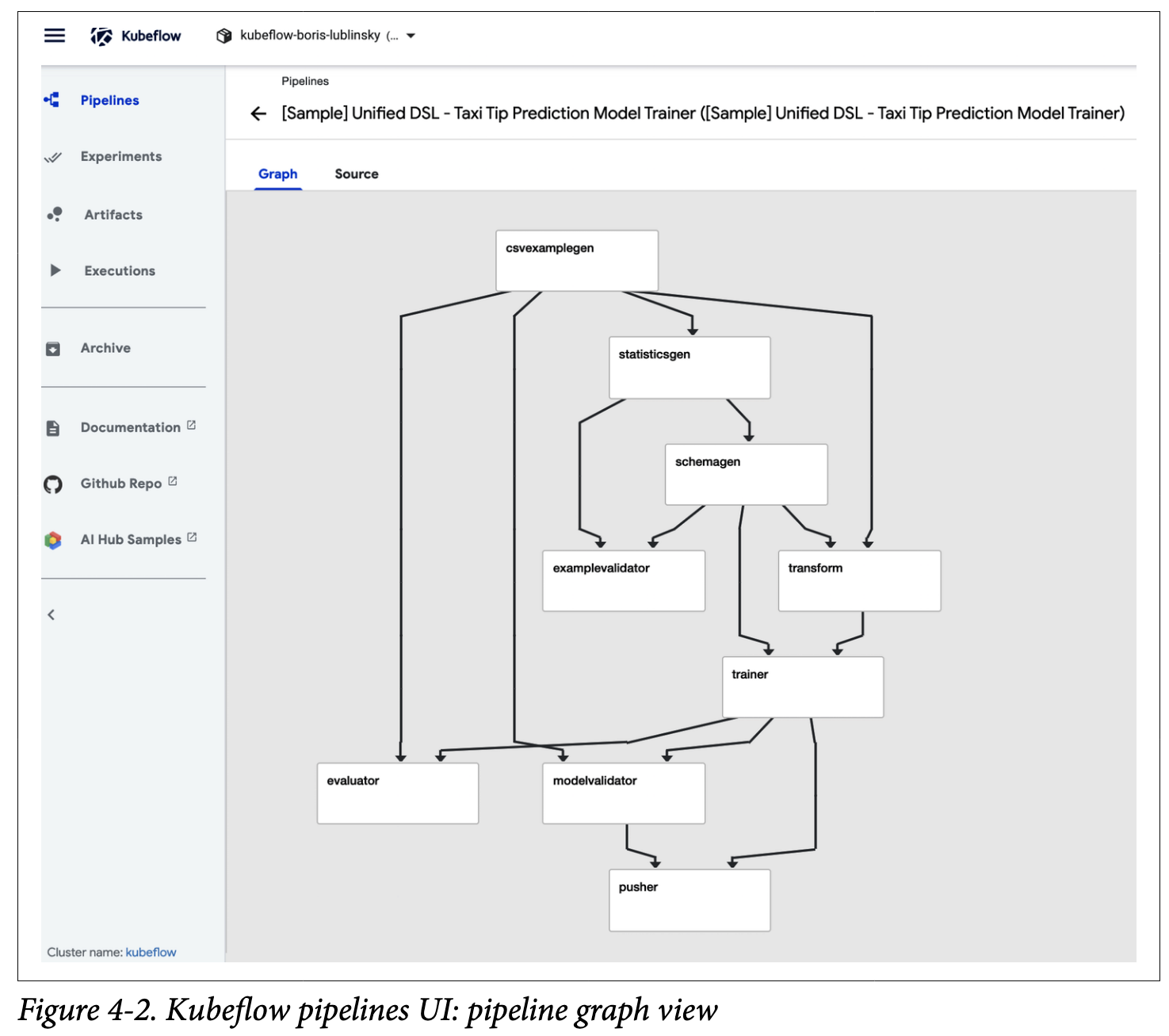
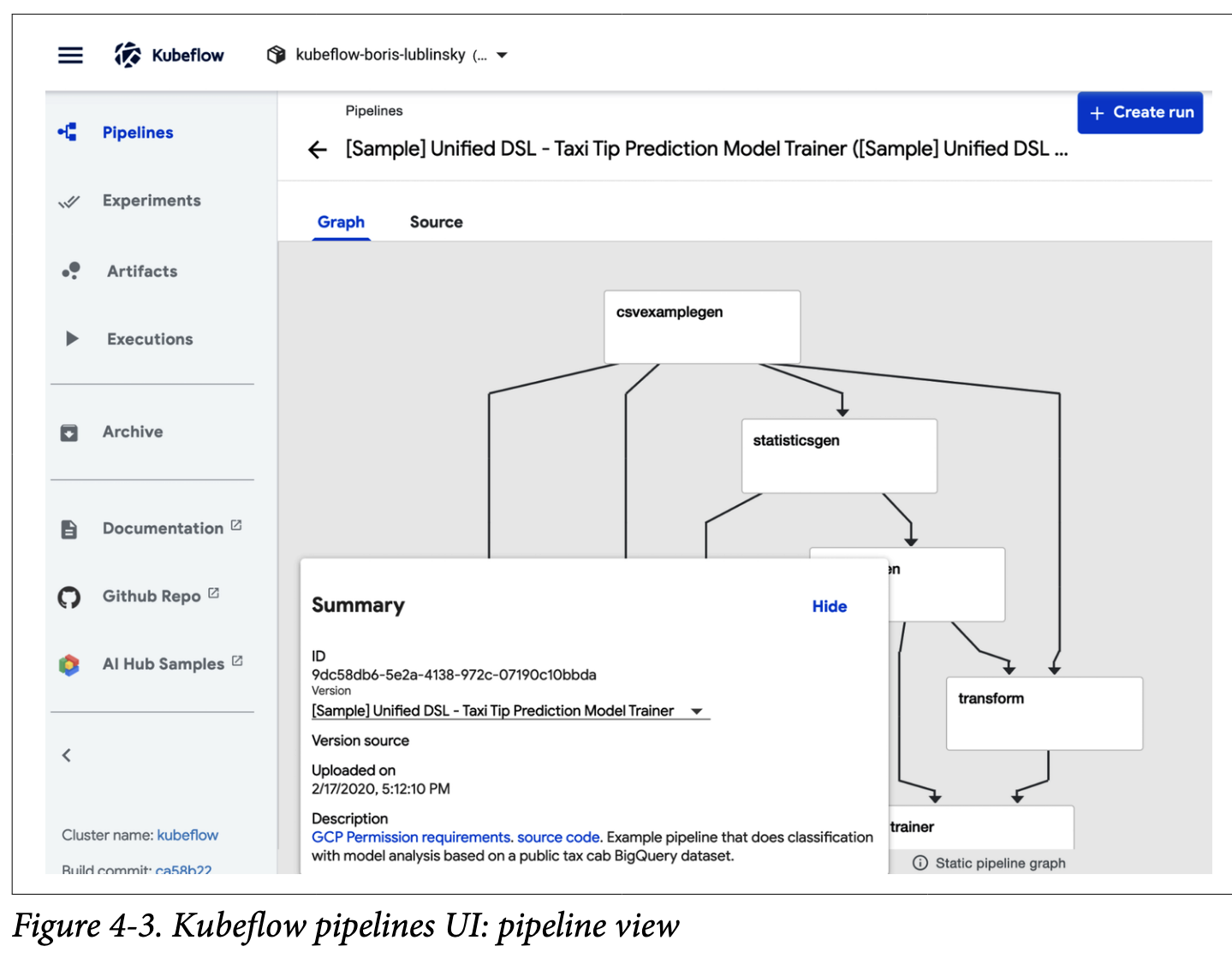
要调用特定的管道,只需单击它;这将显示管道视图,如图所示。
2、在Python中构建一个简单的管道
我们已经了解了如何执行预编译的Kubeflow管道,现在让我们研究一下如何编写我们自己的新管道。Kubeflow公开了用于创作管道的Python域特定语言(DSL)。DSL是ML工作流中执行的操作的Pythonic表示,是专门为ML工作负载构建的。DSL还允许一些简单的Python函数用作管道阶段,而不必显式构建容器。
“域特定语言”(DSL,Domain-Specific Language)是一种专门为某个特定领域或任务设计的编程语言。与通用编程语言(如 Python、Java 等)不同,DSL 旨在提供更高效、更简洁的工具来解决特定领域的问题。它通常有专门的语法和功能,能够让开发者更专注于特定问题,而不必关心其他不相关的细节。
举个例子:
1. SQL(结构化查询语言)是一个用于数据库操作的 DSL。它被设计得非常适合查询、插入、更新和删除数据库中的数据,而不适用于一般的软件开发任务。
2. HTML/CSS 是用于网页设计的 DSL。HTML 专注于网页内容的结构,而 CSS 专注于页面的样式。
3. 正则表达式(Regex),用于文本模式匹配,也是一个 DSL,专门为文本处理设计。
管道本质上是容器执行的图。除了指定哪些容器应该以哪个顺序运行之外,它还允许用户向整个管道以及在参与的容器之间传递参数。
对于每个容器(使用Python SDK时),我们必须:
创建容器:可以作为简单的Python函数,也可以使用任何Docker容器
创建一个引用该容器以及命令行参数、数据装载和变量的操作来传递容器。
对操作进行排序,定义哪些操作可以并行进行,哪些操作必须在进入下一步之前完成。
将这个用Python定义的管道编译成Kubeflow管道可以使用的YAML文件。
对于我们的第一个Kubeflow操作,我们将使用一种称为轻量级Python函数的技术。在轻量级Python函数中,我们定义一个Python函数,然后让Kubeflow负责将该函数打包到容器中并创建一个操作。
为了简单起见,让我们将最简单的函数声明为echo。这是一个接受单个输入(一个整数)并返回该输入的函数。
让我们从导入kfp并定义我们的函数开始:
import kfp
def simple_echo(i: int) -> int:
return i接下来,我们希望将函数simple_echo包装成一个Kubeflow管道操作。有一个很好的小方法可以做到这一点:kfp.components.func_to_container_op。此方法返回一个带有强类型签名的工厂函数:
simpleStronglyTypedFunction = kfp.components.func_to_container_op(deadSimpleIntEchoFn)当我们下一步创建管道时,工厂函数会构造一个ContainerOp,它会在一个容器中运行原始函数(echo_fn):
foo = simpleStronglyTypedFunction(1)如果你的代码可以被GPU加速,很容易将一个阶段标记为使用GPU资源;只需添加。set_gpu_limit(NUM_GPUS)到您的容器。
现在让我们将容器(只有一个)排序到管道中。这个管道将接受一个参数(我们将回显的数字)。管道还有一些与之相关的元数据。虽然回显数字可能是参数的一种微不足道的使用,但在现实世界的用例中,您可能会包含稍后可能想要调整的变量,例如机器学习算法的超参数。
最后,我们将管道编译成一个压缩的YAML文件,然后可以将其上传到管道UI。
@kfp.dsl.pipeline(
name='Simple Echo',
description='This is an echo pipeline. It echoes numbers.'
)
def echo_pipeline(param_1: kfp.dsl.PipelineParam):
my_step = simpleStronglyTypedFunction(i= param_1)
kfp.compiler.Compiler().compile(echo_pipeline, 'echo-pipeline.zip')只有一个组件的管道不是很有趣。对于下一个例子,我们将定制轻量级Python函数的容器。我们将创建一个新的管道,用于安装和导入其他Python库,从指定的基本映像构建,并在容器之间传递输出。
我们将创建一个管道,将一个数除以另一个数,然后添加第三个数。首先让我们创建简单的add函数,如示例4-1所示。

接下来,让我们创建一个稍微复杂一点的函数。此外,让这个函数从Python库numpy导入。这必须在函数内完成。这是因为来自notebook的全局导入不会打包到我们创建的容器中。当然,确保我们的容器安装了我们要导入的库也很重要。
为此,我们将要用作基镜像的特定容器传递给.func_to_container(如示例4-2所示。

①:在函数内部导入库。
②:轻量级Python函数内部的嵌套函数也是可以的。
③:调用特定的基础容器。
现在我们将建造一条管道。示例4-3中的管道使用前面定义的函数my_divmod和add作为阶段。

①:在容器之间传递的值。由此推断出操作顺序。
最后,我们使用客户端提交管道进行执行,这将返回执行和实验的链接。实验将处决分组在一起。如果您愿意,还可以使用kfp.compiler.Compiler().编译并上传zip文件,如第一个示例所示:

按照create_run_from_pipeline_func返回的链接,我们可以进入执行web UI,它显示管道本身和中间结果,如图4-4所示。
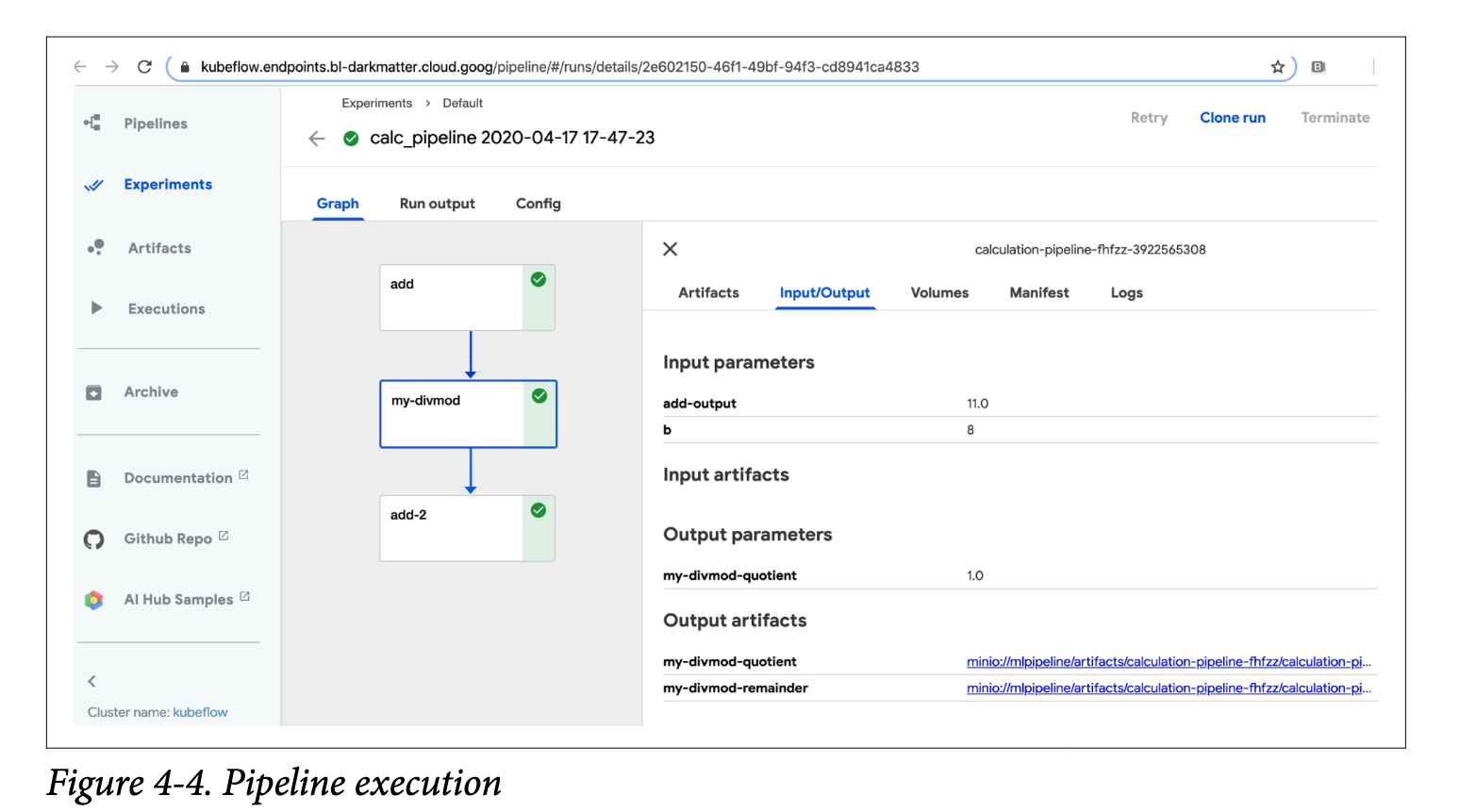
正如我们所看到的,轻量级Python函数中的轻量级是指在我们的过程中执行这些步骤的容易程度,而不是函数本身的能力。我们可以使用自定义导入、基本图像以及如何在容器之间传递小结果。
3、Kubeflow Pipelines组件介绍
Kubeflow Pipelines建立在Argo Workflows之上,Argo Workflows是一个用于Kubernetes的开源容器原生工作流引擎。在本节中,我们将描述Argo如何工作,它做什么,以及Kubeflow Pipeline如何补充Argo,使其更容易被数据科学家使用。
Kubeflow安装所有Argo组件。虽然在计算机上安装Argo并不是使用Kubeflow管道的必要条件,但拥有Argo命令行工具可以更容易地理解和调试管道。
Argo是工作流执行的基础;然而,直接使用它需要你做一些尴尬的事情。首先,您必须在YAML中定义您的工作流程,这可能很困难。其次,您必须将代码容器化,这可能会很乏味。KF Pipelines的主要优势是您可以使用Python API来定义/创建管道,这可以自动生成用于工作流定义的大部分YAML样板,并且对于数据科学家/Python开发人员来说非常友好。Kubeflow Pipelines还具有为机器学习特定组件添加构建块的挂钩。这些API不仅生成YAML,还可以简化容器创建和资源使用。除了API之外,Kubeflow还添加了一个用于配置和执行的重复调度程序和UI。

