

volcano plugin-2
nodeorder
nodeorder 是 Volcano 调度器的核心插件之一,用于实现节点排序策略的加权组合,基于多种调度算法的综合得分决定任务的最佳部署节点。支持原生 Kubernetes 的多种调度策略,通过用户定义的权重参数灵活调整各策略的影响力。
核心功能:
多策略集成:整合 Kubernetes 原生调度策略(资源分配、亲和性、拓扑分布等)
权重配置:允许为不同策略设置优先级权重
批量评分:并行处理节点评分,优化大规模集群性能
综合评分:加权求和各策略得分,确定节点优先级
通过参数配置权重
arguments:
leastrequested.weight: 1 # 最少资源请求权重
mostrequested.weight: 0 # 最多资源请求权重(默认禁用)
nodeaffinity.weight: 2 # 节点亲和性权重
podaffinity.weight: 2 # Pod间亲和性权重
balancedresource.weight: 1 # 资源均衡分配权重
tainttoleration.weight: 3 # 污点容忍权重
imagelocality.weight: 1 # 镜像本地性权重
podtopologyspread.weight: 2 # 拓扑分布权重nodeOrderFn按顺序计算各策略得分并加权求和:
镜像本地性 (
ImageLocality)优先选择已有任务所需镜像的节点
权重影响:
score * imageLocalityWeight
资源分配策略:
最少请求 (
LeastAllocated)偏好资源剩余最多的节点
公式:
(节点可用资源 / 总量) * 100
最多请求 (
MostAllocated)偏好资源利用率高的节点(适合批处理场景)
均衡分配 (
BalancedAllocation)确保 CPU、内存、GPU 等资源的均衡使用
计算各项资源的利用率方差,方差越小得分越高
节点亲和性 (
NodeAffinity)匹配节点标签与 Pod 的
nodeSelector/nodeAffinity
日志记录:各策略得分与权重乘积记录在 V5 级别日志,便于调试
nodeOrderFn := func(task *api.TaskInfo, node *api.NodeInfo) (float64, error) {
var nodeScore = 0.0
state := k8sframework.NewCycleState()
if weight.imageLocalityWeight != 0 {
score, status := imageLocality.Score(context.TODO(), state, task.Pod, node.Name)
if !status.IsSuccess() {
klog.Warningf("Node: %s, Image Locality Priority Failed because of Error: %v", node.Name, status.AsError())
return 0, status.AsError()
}
// If imageLocalityWeight is provided, host.Score is multiplied with weight, if not, host.Score is added to total score.
nodeScore += float64(score) * float64(weight.imageLocalityWeight)
klog.V(5).Infof("Node: %s, task<%s/%s> Image Locality weight %d, score: %f", node.Name, task.Namespace, task.Name, weight.imageLocalityWeight, float64(score)*float64(weight.imageLocalityWeight))
}
// NodeResourcesLeastAllocated
if weight.leastReqWeight != 0 {
score, status := leastAllocated.Score(context.TODO(), state, task.Pod, node.Name)
if !status.IsSuccess() {
klog.Warningf("Node: %s, Least Allocated Priority Failed because of Error: %v", node.Name, status.AsError())
return 0, status.AsError()
}
// If leastReqWeight is provided, host.Score is multiplied with weight, if not, host.Score is added to total score.
nodeScore += float64(score) * float64(weight.leastReqWeight)
klog.V(5).Infof("Node: %s, task<%s/%s> Least Request weight %d, score: %f", node.Name, task.Namespace, task.Name, weight.leastReqWeight, float64(score)*float64(weight.leastReqWeight))
}
// NodeResourcesMostAllocated
if weight.mostReqWeight != 0 {
score, status := mostAllocation.Score(context.TODO(), state, task.Pod, node.Name)
if !status.IsSuccess() {
klog.Warningf("Node: %s, Most Allocated Priority Failed because of Error: %v", node.Name, status.AsError())
return 0, status.AsError()
}
// If mostRequestedWeight is provided, host.Score is multiplied with weight, it's 0 by default
nodeScore += float64(score) * float64(weight.mostReqWeight)
klog.V(5).Infof("Node: %s, task<%s/%s> Most Request weight %d, score: %f", node.Name, task.Namespace, task.Name, weight.mostReqWeight, float64(score)*float64(weight.mostReqWeight))
}
// NodeResourcesBalancedAllocation
if weight.balancedResourceWeight != 0 {
score, status := balancedAllocation.Score(context.TODO(), state, task.Pod, node.Name)
if !status.IsSuccess() {
klog.Warningf("Node: %s, Balanced Resource Allocation Priority Failed because of Error: %v", node.Name, status.AsError())
return 0, status.AsError()
}
// If balancedResourceWeight is provided, host.Score is multiplied with weight, if not, host.Score is added to total score.
nodeScore += float64(score) * float64(weight.balancedResourceWeight)
klog.V(5).Infof("Node: %s, task<%s/%s> Balanced Request weight %d, score: %f", node.Name, task.Namespace, task.Name, weight.balancedResourceWeight, float64(score)*float64(weight.balancedResourceWeight))
}
// NodeAffinity
if weight.nodeAffinityWeight != 0 {
score, status := nodeAffinity.Score(context.TODO(), state, task.Pod, node.Name)
if !status.IsSuccess() {
klog.Warningf("Node: %s, Calculate Node Affinity Priority Failed because of Error: %v", node.Name, status.AsError())
return 0, status.AsError()
}
// TODO: should we normalize the score
// If nodeAffinityWeight is provided, host.Score is multiplied with weight, if not, host.Score is added to total score.
nodeScore += float64(score) * float64(weight.nodeAffinityWeight)
klog.V(5).Infof("Node: %s, task<%s/%s> Node Affinity weight %d, score: %f", node.Name, task.Namespace, task.Name, weight.nodeAffinityWeight, float64(score)*float64(weight.nodeAffinityWeight))
}
klog.V(4).Infof("Nodeorder Total Score for task<%s/%s> on node %s is: %f", task.Namespace, task.Name, node.Name, nodeScore)
return nodeScore, nil
}并行处理三大策略:
Pod间亲和性 (
InterPodAffinity)基于 Pod 的亲和/反亲和规则计算节点得分
污点容忍 (
TaintToleration)根据 Pod 的容忍配置过滤不可调度的节点
拓扑分布 (
PodTopologySpread)确保 Pod 在指定拓扑域(如机架、区域)内均匀分布
并行机制:使用
workqueue.ParallelizeUntil分 16 个 Worker 并行计算得分归一化:各策略得分标准化到
[0, 100]区间后加权求和
batchNodeOrderFn := func(task *api.TaskInfo, nodeInfo []*api.NodeInfo) (map[string]float64, error) {
// InterPodAffinity
state := k8sframework.NewCycleState()
nodeInfos := make([]*k8sframework.NodeInfo, 0, len(nodeInfo))
nodes := make([]*v1.Node, 0, len(nodeInfo))
for _, node := range nodeInfo {
newNodeInfo := &k8sframework.NodeInfo{}
newNodeInfo.SetNode(node.Node)
nodeInfos = append(nodeInfos, newNodeInfo)
nodes = append(nodes, node.Node)
}
nodeScores := make(map[string]float64, len(nodes))
podAffinityScores, podErr := interPodAffinityScore(interPodAffinity, state, task.Pod, nodeInfos, weight.podAffinityWeight)
if podErr != nil {
return nil, podErr
}
nodeTolerationScores, err := taintTolerationScore(taintToleration, state, task.Pod, nodeInfos, weight.taintTolerationWeight)
if err != nil {
return nil, err
}
podTopologySpreadScores, err := podTopologySpreadScore(podTopologySpread, state, task.Pod, nodeInfos, weight.podTopologySpreadWeight)
if err != nil {
return nil, err
}
for _, node := range nodes {
nodeScores[node.Name] = podAffinityScores[node.Name] + nodeTolerationScores[node.Name] + podTopologySpreadScores[node.Name]
}
klog.V(4).Infof("Batch Total Score for task %s/%s is: %v", task.Namespace, task.Name, nodeScores)
return nodeScores, nil
}func interPodAffinityScore(
interPodAffinity *interpodaffinity.InterPodAffinity,
state *k8sframework.CycleState,
pod *v1.Pod,
nodeInfos []*k8sframework.NodeInfo,
podAffinityWeight int,
) (map[string]float64, error) {
preScoreStatus := interPodAffinity.PreScore(context.TODO(), state, pod, nodeInfos)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
nodeScoreList := make(k8sframework.NodeScoreList, len(nodeInfos))
workerNum := 16
errCh := make(chan error, workerNum)
parallelizeContext, parallelizeCancel := context.WithCancel(context.TODO())
defer parallelizeCancel()
workqueue.ParallelizeUntil(parallelizeContext, workerNum, len(nodeInfos), func(index int) {
nodeName := nodeInfos[index].Node().Name
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
s, status := interPodAffinity.Score(ctx, state, pod, nodeName)
if !status.IsSuccess() {
parallelizeCancel()
errCh <- fmt.Errorf("calculate inter pod affinity priority failed %v", status.Message())
return
}
nodeScoreList[index] = k8sframework.NodeScore{
Name: nodeName,
Score: s,
}
})
select {
case err := <-errCh:
return nil, err
default:
}
interPodAffinity.NormalizeScore(context.TODO(), state, pod, nodeScoreList)
nodeScores := make(map[string]float64, len(nodeInfos))
for i, nodeScore := range nodeScoreList {
// return error if score plugin returns invalid score.
if nodeScore.Score > k8sframework.MaxNodeScore || nodeScore.Score < k8sframework.MinNodeScore {
return nil, fmt.Errorf("inter pod affinity returns an invalid score %v for node %s", nodeScore.Score, nodeScore.Name)
}
nodeScore.Score *= int64(podAffinityWeight)
nodeScoreList[i] = nodeScore
nodeScores[nodeScore.Name] = float64(nodeScore.Score)
}
klog.V(4).Infof("inter pod affinity Score for task %s/%s is: %v", pod.Namespace, pod.Name, nodeScores)
return nodeScores, nil
}nodeorder 插件通过多策略加权机制,为 Volcano 提供了高度可定制的节点排序能力。其核心价值在于平衡资源效率、拓扑约束与业务亲和性需求,适用于复杂多变的调度场景。通过合理配置权重参数,可有效优化集群资源利用率与任务运行性能。
overcommit
因为是基础资源*1.2构造虚拟资源,所以叫超卖
这个overcommit插件是Volcano调度器中的一个关键组件,主要作用是通过可控的资源超卖机制,在保证集群稳定性的前提下提高资源利用率。以下是核心机制的分析:
虚拟资源池概念:
将物理资源按
overCommitFactor系数(默认1.2)放大,创建虚拟资源池示例:100核物理CPU × 1.2 → 120核虚拟CPU
允许调度器在此虚拟池内进行资源分配
三级资源追踪体系:
TotalResource:物理节点资源总和
IdleResource:虚拟空闲资源 = (Total × overCommitFactor) - 已分配资源
InqueueResource:已入队作业的最低资源需求总和
type overcommitPlugin struct {
// Arguments given for the plugin
pluginArguments framework.Arguments
totalResource *api.Resource
idleResource *api.Resource
inqueueResource *api.Resource
overCommitFactor float64
}func (op *overcommitPlugin) OnSessionOpen(ssn *framework.Session) {
klog.V(5).Infof("Enter overcommit plugin ...")
defer klog.V(5).Infof("Leaving overcommit plugin.")
// 超卖因子需要大于一
op.pluginArguments.GetFloat64(&op.overCommitFactor, overCommitFactor)
if op.overCommitFactor < 1.0 {
klog.Warningf("Invalid input %f for overcommit-factor, reason: overcommit-factor cannot be less than 1,"+
" using default value: %f.", op.overCommitFactor, defaultOverCommitFactor)
op.overCommitFactor = defaultOverCommitFactor
}
// 虚拟池 = ∑节点资源 * overCommitFactor - ∑已用资源
op.totalResource.Add(ssn.TotalResource)
// calculate idle resources of total cluster, overcommit resources included
used := api.EmptyResource()
for _, node := range ssn.Nodes {
used.Add(node.Used)
}
op.idleResource = op.totalResource.Clone().Multi(op.overCommitFactor).SubWithoutAssert(used)
// 计算inqueue的job资源
for _, job := range ssn.Jobs {
// calculate inqueue job resources
if job.PodGroup.Status.Phase == scheduling.PodGroupInqueue && job.PodGroup.Spec.MinResources != nil {
// deduct the resources of scheduling gated tasks in a job when calculating inqueued resources
// so that it will not block other jobs from being inqueued.
op.inqueueResource.Add(job.DeductSchGatedResources(job.GetMinResources()))
continue
}
// 计算running状态的job资源
if job.PodGroup.Status.Phase == scheduling.PodGroupRunning &&
job.PodGroup.Spec.MinResources != nil &&
int32(util.CalculateAllocatedTaskNum(job)) >= job.PodGroup.Spec.MinMember {
inqueued := util.GetInqueueResource(job, job.Allocated)
op.inqueueResource.Add(job.DeductSchGatedResources(inqueued))
}
}
ssn.AddJobEnqueueableFn(op.Name(), func(obj interface{}) int {
job := obj.(*api.JobInfo)
idle := op.idleResource
inqueue := api.EmptyResource()
inqueue.Add(op.inqueueResource)
// 若作业未定义 MinResources(如无资源请求的批处理任务),直接允许入队,避免过度限制灵活性。
if job.PodGroup.Spec.MinResources == nil {
klog.V(4).Infof("Job <%s/%s> is bestEffort, permit to be inqueue.", job.Namespace, job.Name)
return util.Permit
}
jobMinReq := job.GetMinResources()
// 仅校验作业实际请求的资源类型(如作业只请求 GPU,则不检查 CPU/Memory 余量):
if inqueue.Add(jobMinReq).LessEqualWithDimension(idle, jobMinReq) {
klog.V(4).Infof("Sufficient resources, permit job <%s/%s> to be inqueue", job.Namespace, job.Name)
return util.Permit
}
klog.V(4).Infof("Resource in cluster is overused, reject job <%s/%s> to be inqueue",
job.Namespace, job.Name)
// 若已入队资源总量 + 当前作业需求超过虚拟空闲资源,触发拒绝:
ssn.RecordPodGroupEvent(job.PodGroup, v1.EventTypeNormal, string(scheduling.PodGroupUnschedulableType), "resource in cluster is overused")
return util.Reject
})
ssn.AddJobEnqueuedFn(op.Name(), func(obj interface{}) {
job := obj.(*api.JobInfo)
// 只有非 BestEffort 作业更新资源
if job.PodGroup.Spec.MinResources == nil {
return
}
jobMinReq := job.GetMinResources()
op.inqueueResource.Add(job.DeductSchGatedResources(jobMinReq))
})
}综上所述,这个插件的作用就是:
根据基础硬件资源*1.2构造虚拟资源池
对于没有指定最低资源的Job直接入队
对于指定了资源需求的Job,判断一下当前虚拟资源池中可用资源是否可以满足这个Job,如果可以满足则入队。
predicates
predicates 是 Volcano 调度器中负责节点过滤(Predicate)的核心插件,整合了 Kubernetes 原生调度器的多个过滤逻辑,确保任务调度时满足资源约束、策略限制。
主要功能包括:
多维度资源校验:端口冲突、存储卷限制、亲和性等
策略控制:污点容忍、拓扑分布约束、资源比例检查
性能优化:缓存机制减少重复计算
设备管理扩展:GPU 等特殊设备的分配跟踪
type predicateEnable struct {
nodeAffinityEnable bool
nodePortEnable bool
taintTolerationEnable bool
podAffinityEnable bool
nodeVolumeLimitsEnable bool
volumeZoneEnable bool
podTopologySpreadEnable bool
cacheEnable bool
proportionalEnable bool
proportional map[v1.ResourceName]baseResource
}可配置的参数:
arguments:
predicate.NodeAffinityEnable: true # 节点亲和性
predicate.NodePortsEnable: true # 端口冲突检查
predicate.TaintTolerationEnable: true # 污点容忍
predicate.PodAffinityEnable: true # Pod 亲和性/反亲和性
predicate.PodTopologySpreadEnable: true # 拓扑分布约束
predicate.CacheEnable: true # 结果缓存enablePredicate解析插件参数,确定启用的 Predicate 功能
设置默认开启的 Predicate 列表
读取用户配置,覆盖默认值
解析比例校验参数(如 GPU 相关资源配比)
func enablePredicate(args framework.Arguments) predicateEnable {
/*
User Should give predicatesEnable in this format(predicate.GPUSharingEnable).
Currently supported only GPUSharing predicate checks.
actions: "reclaim, allocate, backfill, preempt"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- plugins:
- name: drf
- name: predicates
arguments:
predicate.NodeAffinityEnable: true
predicate.NodePortsEnable: true
predicate.TaintTolerationEnable: true
predicate.PodAffinityEnable: true
predicate.NodeVolumeLimitsEnable: true
predicate.VolumeZoneEnable: true
predicate.PodTopologySpreadEnable: true
predicate.GPUSharingEnable: true
predicate.GPUNumberEnable: true
predicate.CacheEnable: true
predicate.ProportionalEnable: true
predicate.resources: nvidia.com/gpu
predicate.resources.nvidia.com/gpu.cpu: 4
predicate.resources.nvidia.com/gpu.memory: 8
- name: proportion
- name: nodeorder
*/
predicate := predicateEnable{
nodeAffinityEnable: true,
nodePortEnable: true,
taintTolerationEnable: true,
podAffinityEnable: true,
nodeVolumeLimitsEnable: true,
volumeZoneEnable: true,
podTopologySpreadEnable: true,
cacheEnable: false,
proportionalEnable: false,
}
// Checks whether predicate enable args is provided or not.
// If args were given by scheduler configmap, cover the values in predicateEnable struct.
args.GetBool(&predicate.nodeAffinityEnable, NodeAffinityEnable)
args.GetBool(&predicate.nodePortEnable, NodePortsEnable)
args.GetBool(&predicate.taintTolerationEnable, TaintTolerationEnable)
args.GetBool(&predicate.podAffinityEnable, PodAffinityEnable)
args.GetBool(&predicate.nodeVolumeLimitsEnable, NodeVolumeLimitsEnable)
args.GetBool(&predicate.volumeZoneEnable, VolumeZoneEnable)
args.GetBool(&predicate.podTopologySpreadEnable, PodTopologySpreadEnable)
args.GetBool(&predicate.cacheEnable, CachePredicate)
// Checks whether predicate.ProportionalEnable is provided or not, if given, modifies the value in predicateEnable struct.
args.GetBool(&predicate.proportionalEnable, ProportionalPredicate)
resourcesProportional := make(map[v1.ResourceName]baseResource)
resourcesStr, ok := args[ProportionalResource].(string)
if !ok {
resourcesStr = ""
}
resources := strings.Split(resourcesStr, ",")
for _, resource := range resources {
resource = strings.TrimSpace(resource)
if resource == "" {
continue
}
// proportional.resources.[ResourceName]
cpuResourceKey := ProportionalResourcesPrefix + resource + ".cpu"
cpuResourceRate := 1.0
args.GetFloat64(&cpuResourceRate, cpuResourceKey)
if cpuResourceRate < 0 {
cpuResourceRate = 1.0
}
memoryResourceKey := ProportionalResourcesPrefix + resource + ".memory"
memoryResourceRate := 1.0
args.GetFloat64(&memoryResourceRate, memoryResourceKey)
if memoryResourceRate < 0 {
memoryResourceRate = 1.0
}
r := baseResource{
CPU: cpuResourceRate,
Memory: memoryResourceRate,
}
resourcesProportional[v1.ResourceName(resource)] = r
}
predicate.proportional = resourcesProportional
return predicate
}func (pp *predicatesPlugin) OnSessionOpen(ssn *framework.Session) {
pl := ssn.PodLister
nodeMap := ssn.NodeMap
pCache := predicateCacheNew()
predicate := enablePredicate(pp.pluginArguments)
// 功能:维护节点资源状态
// 分配时:
// 更新 Pod 所在节点信息
// 处理 GPU 等设备的分配(调用 devices.Allocate)
// 取消分配时:
// 释放设备资源(devices.Release)
// 移除节点上的 Pod 记录
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
klog.V(4).Infoln("predicates, allocate", event.Task.NodeName)
pod := pl.UpdateTask(event.Task, event.Task.NodeName)
nodeName := event.Task.NodeName
node, found := nodeMap[nodeName]
if !found {
klog.Errorf("predicates, update pod %s/%s allocate to NOT EXIST node [%s]", pod.Namespace, pod.Name, nodeName)
return
}
nodeInfo, ok := ssn.Nodes[nodeName]
if !ok {
klog.Errorf("Failed to get node %s info from cache", nodeName)
return
}
//predicate gpu sharing
for _, val := range api.RegisteredDevices {
if devices, ok := nodeInfo.Others[val].(api.Devices); ok {
if !devices.HasDeviceRequest(pod) {
continue
}
err := devices.Allocate(ssn.KubeClient(), pod)
if err != nil {
klog.Errorf("AllocateToPod failed %s", err.Error())
return
}
} else {
klog.Warningf("Devices %s assertion conversion failed, skip", val)
}
}
node.AddPod(pod)
klog.V(4).Infof("predicates, update pod %s/%s allocate to node [%s]", pod.Namespace, pod.Name, nodeName)
},
DeallocateFunc: func(event *framework.Event) {
klog.V(4).Infoln("predicates, deallocate", event.Task.NodeName)
pod := pl.UpdateTask(event.Task, "")
nodeName := event.Task.NodeName
node, found := nodeMap[nodeName]
if !found {
klog.Errorf("predicates, update pod %s/%s allocate from NOT EXIST node [%s]", pod.Namespace, pod.Name, nodeName)
return
}
nodeInfo, ok := ssn.Nodes[nodeName]
if !ok {
klog.Errorf("Failed to get node %s info from cache", nodeName)
return
}
for _, val := range api.RegisteredDevices {
if devices, ok := nodeInfo.Others[val].(api.Devices); ok {
if !devices.HasDeviceRequest(pod) {
continue
}
// deallocate pod gpu id
err := devices.Release(ssn.KubeClient(), pod)
if err != nil {
klog.Errorf("Device %s release failed for pod %s/%s, err:%s", val, pod.Namespace, pod.Name, err.Error())
return
}
} else {
klog.Warningf("Devices %s assertion conversion failed, skip", val)
}
}
err := node.RemovePod(klog.FromContext(context.TODO()), pod)
if err != nil {
klog.Errorf("predicates, remove pod %s/%s from node [%s] error: %v", pod.Namespace, pod.Name, nodeName, err)
return
}
klog.V(4).Infof("predicates, update pod %s/%s deallocate from node [%s]", pod.Namespace, pod.Name, nodeName)
},
})
features := feature.Features{
EnableVolumeCapacityPriority: utilFeature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableNodeInclusionPolicyInPodTopologySpread: utilFeature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: utilFeature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnableSidecarContainers: utilFeature.DefaultFeatureGate.Enabled(features.SidecarContainers),
}
// Initialize k8s plugins
// TODO: Add more predicates, k8s.io/kubernetes/pkg/scheduler/framework/plugins/legacy_registry.go
handle := k8s.NewFrameworkHandle(nodeMap, ssn.KubeClient(), ssn.InformerFactory())
// 1. NodeUnschedulable
plugin, _ := nodeunschedulable.New(context.TODO(), nil, handle)
nodeUnscheduleFilter := plugin.(*nodeunschedulable.NodeUnschedulable)
// 2. NodeAffinity
nodeAffinityArgs := config.NodeAffinityArgs{
AddedAffinity: &v1.NodeAffinity{},
}
plugin, _ = nodeaffinity.New(context.TODO(), &nodeAffinityArgs, handle)
nodeAffinityFilter := plugin.(*nodeaffinity.NodeAffinity)
// 3. NodePorts
plugin, _ = nodeports.New(context.TODO(), nil, handle)
nodePortFilter := plugin.(*nodeports.NodePorts)
// 4. TaintToleration
plugin, _ = tainttoleration.New(context.TODO(), nil, handle, features)
tolerationFilter := plugin.(*tainttoleration.TaintToleration)
// 5. InterPodAffinity
plArgs := &config.InterPodAffinityArgs{}
plugin, _ = interpodaffinity.New(context.TODO(), plArgs, handle)
podAffinityFilter := plugin.(*interpodaffinity.InterPodAffinity)
// 6. NodeVolumeLimits
plugin, _ = nodevolumelimits.NewCSI(context.TODO(), nil, handle, features)
nodeVolumeLimitsCSIFilter := plugin.(*nodevolumelimits.CSILimits)
// 7. VolumeZone
plugin, _ = volumezone.New(context.TODO(), nil, handle)
volumeZoneFilter := plugin.(*volumezone.VolumeZone)
// 8. PodTopologySpread
// Setting cluster level default constraints is not support for now.
ptsArgs := &config.PodTopologySpreadArgs{DefaultingType: config.SystemDefaulting}
plugin, _ = podtopologyspread.New(context.TODO(), ptsArgs, handle, features)
podTopologySpreadFilter := plugin.(*podtopologyspread.PodTopologySpread)
state := k8sframework.NewCycleState()
skipPlugins := make(map[api.TaskID]sets.Set[string])
// 预过滤(AddPrePredicateFn)
// 端口冲突预处理:通过 nodePortFilter.PreFilter
// Pod 亲和性预处理:收集亲和性约束条件
// 拓扑分布预处理:计算拓扑分布需求
ssn.AddPrePredicateFn(pp.Name(), func(task *api.TaskInfo) error {
// Check NodePorts
if predicate.nodePortEnable {
_, status := nodePortFilter.PreFilter(context.TODO(), state, task.Pod)
if err := handleSkipPrePredicatePlugin(status, task, skipPlugins, nodeports.Name); err != nil {
return err
}
}
// Check restartable container
if !features.EnableSidecarContainers && task.HasRestartableInitContainer {
// Scheduler will calculate resources usage for a Pod containing
// restartable init containers that will be equal or more than kubelet will
// require to run the Pod. So there will be no overbooking. However, to
// avoid the inconsistency in resource calculation between the scheduler
// and the older (before v1.28) kubelet, make the Pod unschedulable.
return fmt.Errorf("pod has a restartable init container and the SidecarContainers feature is disabled")
}
if predicate.podAffinityEnable {
_, status := podAffinityFilter.PreFilter(context.TODO(), state, task.Pod)
if err := handleSkipPrePredicatePlugin(status, task, skipPlugins, interpodaffinity.Name); err != nil {
return err
}
}
if predicate.podTopologySpreadEnable {
_, status := podTopologySpreadFilter.PreFilter(context.TODO(), state, task.Pod)
if err := handleSkipPrePredicatePlugin(status, task, skipPlugins, podTopologySpreadFilter.Name()); err != nil {
return err
}
}
return nil
})
/* 按顺序执行以下检查,任一失败即拒绝调度:
- 基础检查:
节点不可调度状态(nodeunschedulable)
节点亲和性(若启用)
污点容忍(若启用)
缓存查询:通过 pCache.PredicateWithCache 加速
- 详细检查:
端口冲突(nodePortFilter)
Pod 亲和性/反亲和性(podAffinityFilter)
存储卷限制(nodeVolumeLimitsCSIFilter)
存储区域匹配(volumeZoneFilter)
拓扑分布约束(podTopologySpreadFilter)
资源比例校验(checkNodeResourceIsProportional)
*/
ssn.AddPredicateFn(pp.Name(), func(task *api.TaskInfo, node *api.NodeInfo) error {
predicateStatus := make([]*api.Status, 0)
nodeInfo, found := nodeMap[node.Name]
if !found {
klog.V(4).Infof("NodeInfo predicates Task <%s/%s> on Node <%s> failed, node info not found",
task.Namespace, task.Name, node.Name)
nodeInfoStatus := &api.Status{
Code: api.Error,
Reason: "node info not found",
Plugin: pp.Name(),
}
predicateStatus = append(predicateStatus, nodeInfoStatus)
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
if node.Allocatable.MaxTaskNum <= len(nodeInfo.Pods) {
klog.V(4).Infof("NodePodNumber predicates Task <%s/%s> on Node <%s> failed, allocatable <%d>, existed <%d>",
task.Namespace, task.Name, node.Name, node.Allocatable.MaxTaskNum, len(nodeInfo.Pods))
podsNumStatus := &api.Status{
Code: api.Unschedulable,
Reason: api.NodePodNumberExceeded,
Plugin: pp.Name(),
}
predicateStatus = append(predicateStatus, podsNumStatus)
}
predicateByStablefilter := func(nodeInfo *k8sframework.NodeInfo) ([]*api.Status, bool, error) {
// CheckNodeUnschedulable
predicateStatus := make([]*api.Status, 0)
status := nodeUnscheduleFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
nodeUnscheduleStatus := api.ConvertPredicateStatus(status)
if nodeUnscheduleStatus.Code != api.Success {
predicateStatus = append(predicateStatus, nodeUnscheduleStatus)
if ShouldAbort(nodeUnscheduleStatus) {
return predicateStatus, false, fmt.Errorf("plugin %s predicates failed %s", nodeUnscheduleFilter.Name(), status.Message())
}
}
// Check NodeAffinity
if predicate.nodeAffinityEnable {
status := nodeAffinityFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
nodeAffinityStatus := api.ConvertPredicateStatus(status)
if nodeAffinityStatus.Code != api.Success {
predicateStatus = append(predicateStatus, nodeAffinityStatus)
if ShouldAbort(nodeAffinityStatus) {
return predicateStatus, false, fmt.Errorf("plugin %s predicates failed %s", nodeAffinityFilter.Name(), status.Message())
}
}
}
// PodToleratesNodeTaints: TaintToleration
if predicate.taintTolerationEnable {
status := tolerationFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
tolerationStatus := api.ConvertPredicateStatus(status)
if tolerationStatus.Code != api.Success {
predicateStatus = append(predicateStatus, tolerationStatus)
if ShouldAbort(tolerationStatus) {
return predicateStatus, false, fmt.Errorf("plugin %s predicates failed %s", tolerationFilter.Name(), status.Message())
}
}
}
return predicateStatus, true, nil
}
// Check PredicateWithCache
var err error
var fit bool
predicateCacheStatus := make([]*api.Status, 0)
if predicate.cacheEnable {
fit, err = pCache.PredicateWithCache(node.Name, task.Pod)
if err != nil {
predicateCacheStatus, fit, _ = predicateByStablefilter(nodeInfo)
pCache.UpdateCache(node.Name, task.Pod, fit)
} else {
if !fit {
err = fmt.Errorf("plugin equivalence cache predicates failed")
predicateCacheStatus = append(predicateCacheStatus, &api.Status{
Code: api.Error, Reason: err.Error(), Plugin: CachePredicate,
})
}
}
} else {
predicateCacheStatus, fit, _ = predicateByStablefilter(nodeInfo)
}
predicateStatus = append(predicateStatus, predicateCacheStatus...)
if !fit {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
// Check NodePort
if predicate.nodePortEnable {
isSkipNodePorts := handleSkipPredicatePlugin(task, skipPlugins, nodePortFilter.Name(), node)
if !isSkipNodePorts {
status := nodePortFilter.Filter(context.TODO(), state, nil, nodeInfo)
nodePortStatus := api.ConvertPredicateStatus(status)
if nodePortStatus.Code != api.Success {
predicateStatus = append(predicateStatus, nodePortStatus)
if ShouldAbort(nodePortStatus) {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
}
}
// Check PodAffinity
if predicate.podAffinityEnable {
isSkipInterPodAffinity := handleSkipPredicatePlugin(task, skipPlugins, podAffinityFilter.Name(), node)
if !isSkipInterPodAffinity {
status := podAffinityFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
podAffinityStatus := api.ConvertPredicateStatus(status)
if podAffinityStatus.Code != api.Success {
// TODO: Currently, preemption is not supported when Pod affinity filtering fails.
// Once supported, the logic here should be removed.
// See https://github.com/volcano-sh/volcano/issues/3845
podAffinityStatus.Code = api.UnschedulableAndUnresolvable
predicateStatus = append(predicateStatus, podAffinityStatus)
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
}
// Check NodeVolumeLimits
if predicate.nodeVolumeLimitsEnable {
status := nodeVolumeLimitsCSIFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
nodeVolumeStatus := api.ConvertPredicateStatus(status)
if nodeVolumeStatus.Code != api.Success {
predicateStatus = append(predicateStatus, nodeVolumeStatus)
if ShouldAbort(nodeVolumeStatus) {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
}
// Check VolumeZone
if predicate.volumeZoneEnable {
status := volumeZoneFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
volumeZoneStatus := api.ConvertPredicateStatus(status)
if volumeZoneStatus.Code != api.Success {
predicateStatus = append(predicateStatus, volumeZoneStatus)
if ShouldAbort(volumeZoneStatus) {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
}
// Check PodTopologySpread
if predicate.podTopologySpreadEnable {
isSkipPodTopologySpreadFilter := handleSkipPredicatePlugin(task, skipPlugins, podTopologySpreadFilter.Name(), node)
if !isSkipPodTopologySpreadFilter {
status := podTopologySpreadFilter.Filter(context.TODO(), state, task.Pod, nodeInfo)
podTopologyStatus := api.ConvertPredicateStatus(status)
if podTopologyStatus.Code != api.Success {
predicateStatus = append(predicateStatus, podTopologyStatus)
if ShouldAbort(podTopologyStatus) {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
}
}
if predicate.proportionalEnable {
// Check ProportionalPredicate
proportionalStatus, _ := checkNodeResourceIsProportional(task, node, predicate.proportional)
if proportionalStatus.Code != api.Success {
predicateStatus = append(predicateStatus, proportionalStatus)
if ShouldAbort(proportionalStatus) {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
}
klog.V(4).Infof("checkNodeResourceIsProportional predicates Task <%s/%s> on Node <%s>: fit %v",
task.Namespace, task.Name, node.Name, fit)
}
if len(predicateStatus) > 0 {
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
return nil
})
}通过复用 Kubernetes 调度器框架(k8sframework),直接调用原生插件:
plugin, _ := nodeaffinity.New(...)
nodeAffinityFilter := plugin.(*nodeaffinity.NodeAffinity)
status := nodeAffinityFilter.Filter(...)已集成的原生 Predicates:
NodeAffinity:节点标签/标签选择器匹配
NodePorts:节点端口占用检查
TaintToleration:污点容忍校验
InterPodAffinity:Pod 间亲和性/反亲和性
VolumeZone:存储卷区域匹配
PodTopologySpread:Pod 拓扑分布约束
缓存优化(predicateCache)
机制:记录节点过滤结果,避免重复计算
回退策略:缓存失效时实时计算并更新缓存
适用场景:高频率调度相同任务时提升性能
predicates插件通过整合 Kubernetes 原生调度策略并扩展 Volcano 特有逻辑(如设备管理),提供了全面的节点过滤能力。其模块化设计允许灵活配置,平衡功能性与性能,是保障集群稳定性和资源利用率的关键组件。
priority
Priority 插件用于实现基于优先级的任务调度与抢占策略,主要功能包括:
任务优先级排序:优先级高的任务优先调度
作业优先级排序:优先级高的作业优先分配资源
抢占控制:基于优先级的任务抢占机制
饥饿检测:判断作业是否需要更多资源启动
func (pp *priorityPlugin) OnSessionOpen(ssn *framework.Session) {
taskOrderFn := func(l interface{}, r interface{}) int {
lv := l.(*api.TaskInfo)
rv := r.(*api.TaskInfo)
klog.V(4).Infof("Priority TaskOrder: <%v/%v> priority is %v, <%v/%v> priority is %v",
lv.Namespace, lv.Name, lv.Priority, rv.Namespace, rv.Name, rv.Priority)
if lv.Priority == rv.Priority {
return 0
}
if lv.Priority > rv.Priority {
return -1
}
return 1
}
// Add Task Order function
ssn.AddTaskOrderFn(pp.Name(), taskOrderFn)
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
klog.V(4).Infof("Priority JobOrderFn: <%v/%v> priority: %d, <%v/%v> priority: %d",
lv.Namespace, lv.Name, lv.Priority, rv.Namespace, rv.Name, rv.Priority)
// 优先级高的任务 (Priority 值大) 排在前面
if lv.Priority > rv.Priority {
return -1
}
if lv.Priority < rv.Priority {
return 1
}
return 0
}
ssn.AddJobOrderFn(pp.Name(), jobOrderFn)
// 跨Job:抢占者 Job 优先级 > 被抢占者 Job 优先级
// 同Job:抢占者 Task 优先级 > 被抢占 Task 优先级
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) ([]*api.TaskInfo, int) {
preemptorJob := ssn.Jobs[preemptor.Job]
var victims []*api.TaskInfo
for _, preemptee := range preemptees {
preempteeJob := ssn.Jobs[preemptee.Job]
if preempteeJob.UID != preemptorJob.UID {
if preempteeJob.Priority >= preemptorJob.Priority { // Preemption between Jobs within Queue
klog.V(4).Infof("Can not preempt task <%v/%v>"+
"because preemptee job has greater or equal job priority (%d) than preemptor (%d)",
preemptee.Namespace, preemptee.Name, preempteeJob.Priority, preemptorJob.Priority)
} else {
victims = append(victims, preemptee)
}
} else { // same job's different tasks should compare task's priority
if preemptee.Priority >= preemptor.Priority {
klog.V(4).Infof("Can not preempt task <%v/%v>"+
"because preemptee task has greater or equal task priority (%d) than preemptor (%d)",
preemptee.Namespace, preemptee.Name, preemptee.Priority, preemptor.Priority)
} else {
victims = append(victims, preemptee)
}
}
}
klog.V(4).Infof("Victims from Priority plugins are %+v", victims)
return victims, util.Permit
}
ssn.AddPreemptableFn(pp.Name(), preemptableFn)
// 饥饿检测:当作业的 就绪任务 + 等待任务 < 总任务数 时,判定为饥饿状态
// 用途:调度器优先处理饥饿作业(需配合其他插件使用)
jobStarvingFn := func(obj interface{}) bool {
ji := obj.(*api.JobInfo)
return ji.ReadyTaskNum()+ji.WaitingTaskNum() < int32(len(ji.Tasks))
}
ssn.AddJobStarvingFns(pp.Name(), jobStarvingFn)
}Job可以配置优先级,task也可以配置优先级,通过事先指定优先级来控制任务的处理顺序。
rescheduling
Rescheduling(重新调度)插件是 Volcano 调度器中的一个高级功能模块,旨在通过 动态调整任务分布 优化集群资源利用率,解决以下问题:
节点负载不均衡:部分节点过载而其他节点闲置
长期低效资源分配:识别并迁移低效任务
热点抑制:防止某些节点成为性能瓶颈
func (rp *reschedulingPlugin) OnSessionOpen(ssn *framework.Session) {
klog.V(5).Infof("Enter rescheduling plugin ...")
defer klog.V(5).Infof("Leaving rescheduling plugin.")
// Parse all the rescheduling strategies and execution interval
Session = ssn
configs := NewReschedulingConfigs()
for _, tier := range ssn.Tiers {
for _, pluginOption := range tier.Plugins {
if pluginOption.Name == PluginName {
configs.parseArguments(pluginOption.Arguments)
break
}
}
}
// 每隔一段时间进行重调度检测
if !timeToRun(configs.interval) {
klog.V(3).Infof("It is not the time to execute rescheduling strategies.")
return
}
// 注册victimfns,根据传入的参数进行函数注册
// 模块解耦:每个策略独立实现受害者选择逻辑
// 目前实现了LowNodeUtilization策略
victimFns := make([]api.VictimTasksFn, 0)
for _, strategy := range configs.strategies {
if VictimFn[strategy.Name] != nil {
klog.V(4).Infof("strategy: %s\n", strategy.Name)
victimFns = append(victimFns, VictimFn[strategy.Name])
}
}
ssn.AddVictimTasksFns(rp.Name(), victimFns)
}默认的重调度测量周期是5min,并且注册了lowNodeUtilization的重调度方法。

var victimsFnForLnu = func(tasks []*api.TaskInfo) []*api.TaskInfo {
victims := make([]*api.TaskInfo, 0)
// parse configuration arguments
utilizationConfig := NewLowNodeUtilizationConf()
parametersConfig := RegisteredStrategyConfigs["lowNodeUtilization"]
var config map[string]interface{}
config, ok := parametersConfig.(map[string]interface{})
if !ok {
klog.Errorln("parameters parse error for lowNodeUtilization")
return victims
}
utilizationConfig.parse(config)
// group the nodes into lowNodes and highNodes
nodeUtilizationList := getNodeUtilization()
lowNodes, highNodes := groupNodesByUtilization(nodeUtilizationList, lowThresholdFilter, highThresholdFilter, *utilizationConfig)
if len(lowNodes) == 0 {
klog.V(4).Infof("The resource utilization of all nodes is above the threshold")
return victims
}
if len(lowNodes) == len(Session.Nodes) {
klog.V(4).Infof("The resource utilization of all nodes is below the threshold")
return victims
}
if len(highNodes) == 0 {
klog.V(4).Infof("The resource utilization of all nodes is below the target threshold")
return victims
}
// select victims from lowNodes
return evictPodsFromSourceNodes(highNodes, lowNodes, tasks, isContinueEvictPods, *utilizationConfig)
}resourcequota
本插件用于在 Volcano 调度器中实现 Kubernetes 命名空间级别的资源配额(ResourceQuota)控制,确保作业调度时不超过预设的资源限制。以下是核心功能及实现细节的详细分析:
func (rq *resourceQuotaPlugin) OnSessionOpen(ssn *framework.Session) {
pendingResources := make(map[string]v1.ResourceList)
// 检查作业的资源请求是否会导致命名空间超出配额限制。
ssn.AddJobEnqueueableFn(rq.Name(), func(obj interface{}) int {
job := obj.(*api.JobInfo)
resourcesRequests := job.PodGroup.Spec.MinResources
if resourcesRequests == nil {
return util.Permit
}
if ssn.NamespaceInfo[api.NamespaceName(job.Namespace)] == nil {
return util.Permit
}
// 遍历命名空间配额
// 筛选配额中定义的资源类型(通过 quotav1.Mask)。
// 累加 待处理请求(pendingResources)和 已使用量(resourceQuota.Used)。
quotas := ssn.NamespaceInfo[api.NamespaceName(job.Namespace)].QuotaStatus
for _, resourceQuota := range quotas {
hardResources := quotav1.ResourceNames(resourceQuota.Hard)
// 仅检查配额中定义的资源类型(如 CPU、内存),忽略其他未定义的资源(如 GPU)。
requestedUsage := quotav1.Mask(*resourcesRequests, hardResources)
var resourcesUsed = resourceQuota.Used
if pendingUse, found := pendingResources[job.Namespace]; found {
resourcesUsed = quotav1.Add(pendingUse, resourcesUsed)
}
newUsage := quotav1.Add(resourcesUsed, requestedUsage)
maskedNewUsage := quotav1.Mask(newUsage, quotav1.ResourceNames(requestedUsage))
// 若请求后的总用量超过配额硬限制,则拒绝入队。
// 记录详细错误信息至 PodGroup 事件。
if allowed, exceeded := quotav1.LessThanOrEqual(maskedNewUsage, resourceQuota.Hard); !allowed {
failedRequestedUsage := quotav1.Mask(requestedUsage, exceeded)
failedUsed := quotav1.Mask(resourceQuota.Used, exceeded)
failedHard := quotav1.Mask(resourceQuota.Hard, exceeded)
msg := fmt.Sprintf("resource quota insufficient, requested: %v, used: %v, limited: %v",
failedRequestedUsage,
failedUsed,
failedHard,
)
klog.V(4).Infof("enqueueable false for job: %s/%s, because :%s", job.Namespace, job.Name, msg)
ssn.RecordPodGroupEvent(job.PodGroup, v1.EventTypeNormal, string(scheduling.PodGroupUnschedulableType), msg)
return util.Reject
}
}
if _, found := pendingResources[job.Namespace]; !found {
pendingResources[job.Namespace] = v1.ResourceList{}
}
pendingResources[job.Namespace] = quotav1.Add(pendingResources[job.Namespace], *resourcesRequests)
return util.Permit
})
}它是多租户集群中资源隔离的基石,确保单个命名空间不会因过度申请而影响全局稳定性。实际部署需结合业务需求动态调整配额值,并通过监控系统跟踪使用率趋势
sla
SLA(Service Level Agreement)插件确保作业在预定时间内完成调度,主要功能包括:
超时管控:设置作业最大等待时间
优先级提升:超时作业自动获得优先调度权
分级配置:支持集群全局和作业级独立配置
arguments:
sla-waiting-time: "2h30m" # 全局默认等待时间(示例值)
job annotations:
sla-waiting-time: "1h" # 作业级覆盖配置func (sp *slaPlugin) OnSessionOpen(ssn *framework.Session) {
klog.V(4).Infof("Enter sla plugin ...")
defer klog.V(4).Infof("Leaving sla plugin.")
// read in sla waiting time for global cluster from sla plugin arguments
// if not set, job waiting time still can set in job yaml separately, otherwise job have no sla limits
if _, exist := sp.pluginArguments[JobWaitingTime]; exist {
waitTime, ok := sp.pluginArguments[JobWaitingTime].(string)
if !ok {
waitTime = ""
}
jwt, err := time.ParseDuration(waitTime)
if err != nil {
klog.Errorf("Error occurs in parsing global job waiting time in sla plugin, err: %s.", err.Error())
}
if jwt <= 0 {
klog.Warningf("Invalid global waiting time setting: %s in sla plugin.", jwt.String())
} else {
sp.jobWaitingTime = &jwt
klog.V(4).Infof("Global job waiting time is %s.", sp.jobWaitingTime.String())
}
}
// 配置了SLA的作业优先于未配置的
// 截止时间早的作业优先
// 同时到期的作业保持原序
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
var lJobWaitingTime = sp.readJobWaitingTime(lv.WaitingTime)
var rJobWaitingTime = sp.readJobWaitingTime(rv.WaitingTime)
if lJobWaitingTime == nil {
if rJobWaitingTime == nil {
return 0
}
return 1
}
if rJobWaitingTime == nil {
return -1
}
lCreationTimestamp := lv.CreationTimestamp
rCreationTimestamp := rv.CreationTimestamp
if lCreationTimestamp.Add(*lJobWaitingTime).Before(rCreationTimestamp.Add(*rJobWaitingTime)) {
return -1
} else if lCreationTimestamp.Add(*lJobWaitingTime).After(rCreationTimestamp.Add(*rJobWaitingTime)) {
return 1
}
return 0
}
ssn.AddJobOrderFn(sp.Name(), jobOrderFn)
permitableFn := func(obj interface{}) int {
jobInfo := obj.(*api.JobInfo)
var jwt = sp.readJobWaitingTime(jobInfo.WaitingTime)
if jwt == nil {
return util.Abstain
}
if time.Since(jobInfo.CreationTimestamp.Time) < *jwt {
return util.Abstain // // 未超时或不干预
}
return util.Permit // // 超时作业立即处理
}
// if job waiting time is over, turn job to be inqueue in enqueue action
ssn.AddJobEnqueueableFn(sp.Name(), permitableFn)
// if job waiting time is over, turn job to be pipelined in allocate action
ssn.AddJobPipelinedFn(sp.Name(), permitableFn)
}usage
usage 插件基于节点资源历史使用率优化调度策略,主要提供两大能力:
过滤机制(Predicate):阻止 Pod 调度到高负载节点
优先级排序(Node Scoring):优先选择低负载节点
type usagePlugin struct {
pluginArguments framework.Arguments
usageWeight int
cpuWeight int
memoryWeight int
usageType string
cpuThresholds float64
memThresholds float64
period string
}func (up *usagePlugin) OnSessionOpen(ssn *framework.Session) {
klog.V(5).Infof("Enter usage plugin ...")
defer func() {
klog.V(5).Infof("Leaving usage plugin ...")
}()
if klog.V(4).Enabled() {
for node, nodeInfo := range ssn.Nodes {
klog.V(4).Infof("node:%v, cpu usage:%v, mem usage:%v, metrics time is %v",
node, nodeInfo.ResourceUsage.CPUUsageAvg, nodeInfo.ResourceUsage.MEMUsageAvg, nodeInfo.ResourceUsage.MetricsTime)
}
}
predicateFn := func(task *api.TaskInfo, node *api.NodeInfo) error {
predicateStatus := make([]*api.Status, 0)
usageStatus := &api.Status{Plugin: PluginName}
// 数据过期或未配置周期时跳过检查
// 避免因监控系统故障导致完全拒绝调度
now := time.Now()
if up.period == "" || now.Sub(node.ResourceUsage.MetricsTime) > MetricsActiveTime {
klog.V(4).Infof("The period(%s) is empty or the usage metrics data is not updated for more than %v minutes, "+
"Usage plugin filter for task %s/%s on node %s pass, metrics time is %v. ", up.period, MetricsActiveTime, task.Namespace, task.Name, node.Name, node.ResourceUsage.MetricsTime)
return nil
}
// if CPU使用率 > 阈值 {
// 记录CPU超限日志
// return 不可调度错误
//}
//if 内存使用率 > 阈值 {
// 记录内存超限日志
// return 不可调度错误
//}
klog.V(4).Infof("predicateFn cpuUsageAvg:%v,predicateFn memUsageAvg:%v", up.cpuThresholds, up.memThresholds)
if node.ResourceUsage.CPUUsageAvg[up.period] > up.cpuThresholds {
klog.V(3).Infof("Node %s cpu usage %f exceeds the threshold %f", node.Name, node.ResourceUsage.CPUUsageAvg[up.period], up.cpuThresholds)
usageStatus.Code = api.UnschedulableAndUnresolvable
usageStatus.Reason = NodeUsageCPUExtend
predicateStatus = append(predicateStatus, usageStatus)
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
if node.ResourceUsage.MEMUsageAvg[up.period] > up.memThresholds {
klog.V(3).Infof("Node %s mem usage %f exceeds the threshold %f", node.Name, node.ResourceUsage.MEMUsageAvg[up.period], up.memThresholds)
usageStatus.Code = api.UnschedulableAndUnresolvable
usageStatus.Reason = NodeUsageMemoryExtend
predicateStatus = append(predicateStatus, usageStatus)
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
klog.V(4).Infof("Usage plugin filter for task %s/%s on node %s pass.", task.Namespace, task.Name, node.Name)
return nil
}
nodeOrderFn := func(task *api.TaskInfo, node *api.NodeInfo) (float64, error) {
score := 0.0
now := time.Now()
if up.period == "" || now.Sub(node.ResourceUsage.MetricsTime) > MetricsActiveTime {
klog.V(4).Infof("The period(%s) is empty or the usage metrics data is not updated for more than %v minutes, "+
"Usage plugin score for task %s/%s on node %s is 0, metrics time is %v. ", up.period, MetricsActiveTime, task.Namespace, task.Name, node.Name, node.ResourceUsage.MetricsTime)
return 0, nil
}
cpuUsage, exist := node.ResourceUsage.CPUUsageAvg[up.period]
klog.V(4).Infof("Node %s cpu usage is %f.", node.Name, cpuUsage)
if !exist {
return 0, nil
}
cpuScore := (100 - cpuUsage) / 100 * float64(up.cpuWeight)
memoryUsage, exist := node.ResourceUsage.MEMUsageAvg[up.period]
klog.V(4).Infof("Node %s memory usage is %f.", node.Name, memoryUsage)
if !exist {
return 0, nil
}
memoryScore := (100 - memoryUsage) / 100 * float64(up.memoryWeight)
score = (cpuScore + memoryScore) / float64(up.cpuWeight+up.memoryWeight)
// MaxNodeScore = 100
score *= float64(k8sFramework.MaxNodeScore * int64(up.usageWeight))
klog.V(4).Infof("Node %s score for task %s is %f.", node.Name, task.Name, score)
return score, nil
}
ssn.AddPredicateFn(up.Name(), predicateFn)
ssn.AddNodeOrderFn(up.Name(), nodeOrderFn)
}具体的评分算法是:
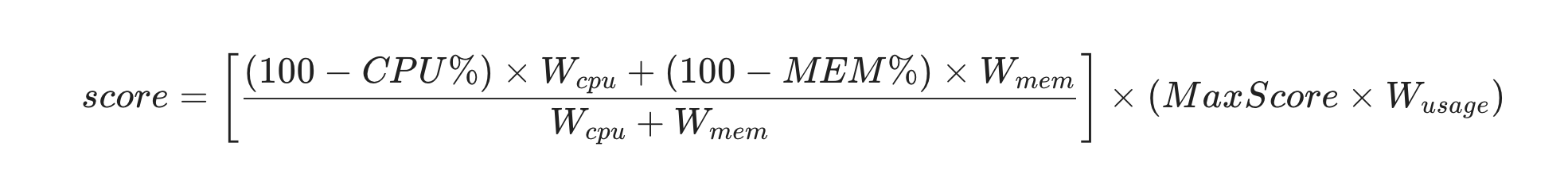
单资源得分:
cpuScore = (100 - cpuUsage) / 100 * cpuWeight
memScore = (100 - memUsage) / 100 * memWeight
加权平均:
avgScore = (cpuScore + memScore) / (cpuWeight + memWeight)
总分调整:
finalScore = avgScore*(100*usageWeight)
综上,这个插件会优先选择具有较低使用率的节点,和binpack相反。
proportion
这个插件主要用于实现基于权重的多队列资源公平分配。以下是对该插件的核心分析:
1、资源按权重比例分配
权重计算:队列的weight属性决定其资源分配比例。总资源按各队列权重值占比进行划分。
实时调整:通过循环分配剩余资源,动态调整队列的deserved资源量,确保资源分配的弹性。
能力限制:每个队列的capability和realCapability限制其资源使用上限,避免单个队列过度占用资源。
2、资源保障与隔离
Guarantee资源保证:队列的guarantee字段确保其最低资源配额,即使集群资源紧张也能优先满足。
弹性资源回收:通过elastic字段追踪作业弹性资源(超出minAvailable的部分),支持资源回收以提高利用率。
3、队列优先级排序
Share值计算:根据allocated/deserved的最大比例计算队列的share,优先调度资源利用率低的队列。
双重排序条件:队列优先级首先按spec.priority,其次按share值排序,确保高优先级和低利用率队列优先调度。
4、作业准入控制
入队检查:通过AddJobEnqueueableFn检查队列的剩余能力(realCapability),若无法满足作业的minResources则拒绝入队,避免资源超售。
动态资源跟踪:实时更新队列的inqueue和allocated资源,确保决策的准确性。
type queueAttr struct {
queueID api.QueueID
name string
weight int32
share float64
deserved *api.Resource // deserved:理论上应得的资源量。
allocated *api.Resource // allocated:当前已分配的资源。
request *api.Resource // request:队列内所有作业请求的资源总和。
elastic *api.Resource // elastic:作业弹性资源(可回收部分)。
inqueue *api.Resource
capability *api.Resource
realCapability *api.Resource // realCapability:队列的实际资源上限(考虑全局保障资源后的能力)。
guarantee *api.Resource
}func (pp *proportionPlugin) OnSessionOpen(ssn *framework.Session) {
// 总资源:pp.totalResource记录集群的可用资源总量(CPU、内存等)。
// 保障资源总和:pp.totalGuarantee汇总所有队列的Spec.Guarantee资源,用于后续计算队列的实际资源上限。
pp.totalResource.Add(ssn.TotalResource)
klog.V(4).Infof("The total resource is <%v>", pp.totalResource)
for _, queue := range ssn.Queues {
if len(queue.Queue.Spec.Guarantee.Resource) == 0 {
continue
}
guarantee := api.NewResource(queue.Queue.Spec.Guarantee.Resource)
pp.totalGuarantee.Add(guarantee)
}
klog.V(4).Infof("The total guarantee resource is <%v>", pp.totalGuarantee)
// 遍历所有作业,为每个队列初始化或更新属性:
// 能力限制:
// capability:队列的静态资源上限(来自Spec.Capability),未配置时视为无限。
// realCapability:动态计算的真实上限,结合集群剩余资源(总资源减去全局保障资源)和队列自身的保障资源,取capability与动态值的最小值。
// 资源统计:
// allocated:已分配给队列的任务资源。
// request:队列内所有作业(包括未调度任务)的资源需求总和。
// elastic:作业弹性资源(已分配资源减去minAvailable)。
for _, job := range ssn.Jobs {
klog.V(4).Infof("Considering Job <%s/%s>.", job.Namespace, job.Name)
if _, found := pp.queueOpts[job.Queue]; !found {
queue := ssn.Queues[job.Queue]
attr := &queueAttr{
queueID: queue.UID,
name: queue.Name,
weight: queue.Weight,
deserved: api.EmptyResource(),
allocated: api.EmptyResource(),
request: api.EmptyResource(),
elastic: api.EmptyResource(),
inqueue: api.EmptyResource(),
guarantee: api.EmptyResource(),
}
if len(queue.Queue.Spec.Capability) != 0 {
attr.capability = api.NewResource(queue.Queue.Spec.Capability)
if attr.capability.MilliCPU <= 0 {
attr.capability.MilliCPU = math.MaxFloat64
}
if attr.capability.Memory <= 0 {
attr.capability.Memory = math.MaxFloat64
}
}
if len(queue.Queue.Spec.Guarantee.Resource) != 0 {
attr.guarantee = api.NewResource(queue.Queue.Spec.Guarantee.Resource)
}
realCapability := api.ExceededPart(pp.totalResource, pp.totalGuarantee).Add(attr.guarantee)
if attr.capability == nil {
attr.realCapability = realCapability
} else {
realCapability.MinDimensionResource(attr.capability, api.Infinity)
attr.realCapability = realCapability
}
pp.queueOpts[job.Queue] = attr
klog.V(4).Infof("Added Queue <%s> attributes.", job.Queue)
}
attr := pp.queueOpts[job.Queue]
for status, tasks := range job.TaskStatusIndex {
if api.AllocatedStatus(status) {
for _, t := range tasks {
attr.allocated.Add(t.Resreq)
attr.request.Add(t.Resreq)
}
} else if status == api.Pending {
for _, t := range tasks {
attr.request.Add(t.Resreq)
}
}
}
if job.PodGroup.Status.Phase == scheduling.PodGroupInqueue {
attr.inqueue.Add(job.DeductSchGatedResources(job.GetMinResources()))
}
// calculate inqueue resource for running jobs
// the judgement 'job.PodGroup.Status.Running >= job.PodGroup.Spec.MinMember' will work on cases such as the following condition:
// Considering a Spark job is completed(driver pod is completed) while the podgroup keeps running, the allocated resource will be reserved again if without the judgement.
if job.PodGroup.Status.Phase == scheduling.PodGroupRunning &&
job.PodGroup.Spec.MinResources != nil &&
int32(util.CalculateAllocatedTaskNum(job)) >= job.PodGroup.Spec.MinMember {
inqueued := util.GetInqueueResource(job, job.Allocated)
// deduct scheduling gated tasks from inqueue resources
attr.inqueue.Add(job.DeductSchGatedResources(inqueued))
}
attr.elastic.Add(job.GetElasticResources())
klog.V(5).Infof("Queue %s allocated <%s> request <%s> inqueue <%s> elastic <%s>",
attr.name, attr.allocated.String(), attr.request.String(), attr.inqueue.String(), attr.elastic.String())
}
// Record metrics
for queueID, queueInfo := range ssn.Queues {
if attr, ok := pp.queueOpts[queueID]; ok {
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
metrics.UpdateQueueRequest(attr.name, attr.request.MilliCPU, attr.request.Memory)
metrics.UpdateQueueWeight(attr.name, attr.weight)
continue
}
metrics.UpdateQueueAllocated(queueInfo.Name, 0, 0)
metrics.UpdateQueueRequest(queueInfo.Name, 0, 0)
}
// 按权分配:剩余资源按队列权重比例分配至deserved字段。
// 资源约束:
// deserved不超过realCapability(能力上限)。
// deserved至少为guarantee(保障资源)与request的较大者。
// 终止条件:
// 所有队列的deserved满足其request。
// 剩余资源为0或无法进一步分配(进入死循环)。
remaining := pp.totalResource.Clone()
meet := map[api.QueueID]struct{}{}
for {
totalWeight := int32(0)
for _, attr := range pp.queueOpts {
if _, found := meet[attr.queueID]; found {
continue
}
totalWeight += attr.weight
}
// If no queues, break
if totalWeight == 0 {
klog.V(4).Infof("Exiting when total weight is 0")
break
}
oldRemaining := remaining.Clone()
// Calculates the deserved of each Queue.
// increasedDeserved is the increased value for attr.deserved of processed queues
// decreasedDeserved is the decreased value for attr.deserved of processed queues
increasedDeserved := api.EmptyResource()
decreasedDeserved := api.EmptyResource()
for _, attr := range pp.queueOpts {
klog.V(4).Infof("Considering Queue <%s>: weight <%d>, total weight <%d>.",
attr.name, attr.weight, totalWeight)
if _, found := meet[attr.queueID]; found {
continue
}
oldDeserved := attr.deserved.Clone()
attr.deserved.Add(remaining.Clone().Multi(float64(attr.weight) / float64(totalWeight)))
if attr.realCapability != nil {
attr.deserved.MinDimensionResource(attr.realCapability, api.Infinity)
}
attr.deserved.MinDimensionResource(attr.request, api.Zero)
attr.deserved = helpers.Max(attr.deserved, attr.guarantee)
pp.updateShare(attr)
klog.V(4).Infof("Format queue <%s> deserved resource to <%v>", attr.name, attr.deserved)
if attr.request.LessEqual(attr.deserved, api.Zero) {
meet[attr.queueID] = struct{}{}
klog.V(4).Infof("queue <%s> is meet", attr.name)
} else if equality.Semantic.DeepEqual(attr.deserved, oldDeserved) {
meet[attr.queueID] = struct{}{}
klog.V(4).Infof("queue <%s> is meet cause of the capability", attr.name)
}
klog.V(4).Infof("The attributes of queue <%s> in proportion: deserved <%v>, realCapability <%v>, allocate <%v>, request <%v>, elastic <%v>, share <%0.2f>",
attr.name, attr.deserved, attr.realCapability, attr.allocated, attr.request, attr.elastic, attr.share)
increased, decreased := attr.deserved.Diff(oldDeserved, api.Zero)
increasedDeserved.Add(increased)
decreasedDeserved.Add(decreased)
// Record metrics
metrics.UpdateQueueDeserved(attr.name, attr.deserved.MilliCPU, attr.deserved.Memory)
}
remaining.Sub(increasedDeserved).Add(decreasedDeserved)
klog.V(4).Infof("Remaining resource is <%s>", remaining)
if remaining.IsEmpty() || equality.Semantic.DeepEqual(remaining, oldRemaining) {
klog.V(4).Infof("Exiting when remaining is empty or no queue has more resource request: <%v>", remaining)
break
}
}
// 1. 按spec.priority(值越大优先级越高)
// 2. 按share值(值越小优先级越高)
// share计算:allocated / deserved的最大比值,反映队列资源利用率。
// 调度顺序:优先调度高优先级(priority)及低利用率(share小)的队列。
ssn.AddQueueOrderFn(pp.Name(), func(l, r interface{}) int {
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
if lv.Queue.Spec.Priority != rv.Queue.Spec.Priority {
// return negative means high priority
return int(rv.Queue.Spec.Priority) - int(lv.Queue.Spec.Priority)
}
if pp.queueOpts[lv.UID].share == pp.queueOpts[rv.UID].share {
return 0
}
if pp.queueOpts[lv.UID].share < pp.queueOpts[rv.UID].share {
return -1
}
return 1
})
// 任务回收(ReclaimableFn):
// 仅回收那些已分配资源超过deserved的任务。
ssn.AddReclaimableFn(pp.Name(), func(reclaimer *api.TaskInfo, reclaimees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
allocations := map[api.QueueID]*api.Resource{}
for _, reclaimee := range reclaimees {
job := ssn.Jobs[reclaimee.Job]
attr := pp.queueOpts[job.Queue]
if _, found := allocations[job.Queue]; !found {
allocations[job.Queue] = attr.allocated.Clone()
}
allocated := allocations[job.Queue]
if allocated.LessPartly(reclaimer.Resreq, api.Zero) {
klog.V(3).Infof("Failed to allocate resource for Task <%s/%s> in Queue <%s>, not enough resource.",
reclaimee.Namespace, reclaimee.Name, job.Queue)
continue
}
if !allocated.LessEqual(attr.deserved, api.Zero) {
allocated.Sub(reclaimee.Resreq)
victims = append(victims, reclaimee)
}
}
klog.V(4).Infof("Victims from proportion plugins are %+v", victims)
return victims, util.Permit
})
// 资源超用检查(OverusedFn):
// 若队列的allocated超过deserved,标记为超用(overused)。
ssn.AddOverusedFn(pp.Name(), func(obj interface{}) bool {
queue := obj.(*api.QueueInfo)
attr := pp.queueOpts[queue.UID]
overused := attr.deserved.LessEqual(attr.allocated, api.Zero)
metrics.UpdateQueueOverused(attr.name, overused)
if overused {
klog.V(3).Infof("Queue <%v>: deserved <%v>, allocated <%v>, share <%v>",
queue.Name, attr.deserved, attr.allocated, attr.share)
}
return overused
})
queueAllocatable := func(queue *api.QueueInfo, candidate *api.TaskInfo) bool {
attr := pp.queueOpts[queue.UID]
futureUsed := attr.allocated.Clone().Add(candidate.Resreq)
allocatable := futureUsed.LessEqualWithDimension(attr.deserved, candidate.Resreq)
if !allocatable {
klog.V(3).Infof("Queue <%v>: deserved <%v>, allocated <%v>; Candidate <%v>: resource request <%v>",
queue.Name, attr.deserved, attr.allocated, candidate.Name, candidate.Resreq)
}
return allocatable
}
ssn.AddAllocatableFn(pp.Name(), func(queue *api.QueueInfo, candidate *api.TaskInfo) bool {
return queueAllocatable(queue, candidate)
})
ssn.AddPreemptiveFn(pp.Name(), func(obj interface{}, candidate interface{}) bool {
queue := obj.(*api.QueueInfo)
task := candidate.(*api.TaskInfo)
return queueAllocatable(queue, task)
})
// 入队检查(JobEnqueueableFn):
// 需满足:allocated + inqueue - elastic + minReq ≤ realCapability。
// 保证新作业的minResources不挤占队列的资源配额。
ssn.AddJobEnqueueableFn(pp.Name(), func(obj interface{}) int {
job := obj.(*api.JobInfo)
queueID := job.Queue
attr := pp.queueOpts[queueID]
queue := ssn.Queues[queueID]
// If no capability is set, always enqueue the job.
if attr.realCapability == nil {
klog.V(4).Infof("Capability of queue <%s> was not set, allow job <%s/%s> to Inqueue.",
queue.Name, job.Namespace, job.Name)
return util.Permit
}
if job.PodGroup.Spec.MinResources == nil {
klog.V(4).Infof("job %s MinResources is null.", job.Name)
return util.Permit
}
minReq := job.GetMinResources()
klog.V(5).Infof("job %s min resource <%s>, queue %s capability <%s> allocated <%s> inqueue <%s> elastic <%s>",
job.Name, minReq.String(), queue.Name, attr.realCapability.String(), attr.allocated.String(), attr.inqueue.String(), attr.elastic.String())
// The queue resource quota limit has not reached
r := minReq.Clone().Add(attr.allocated).Add(attr.inqueue).Sub(attr.elastic)
inqueue := r.LessEqualWithDimension(attr.realCapability, minReq)
klog.V(5).Infof("job %s inqueue %v", job.Name, inqueue)
if inqueue {
// deduct the resources of scheduling gated tasks in a job when calculating inqueued resources
// so that it will not block other jobs from being inqueued.
attr.inqueue.Add(job.DeductSchGatedResources(minReq))
return util.Permit
}
ssn.RecordPodGroupEvent(job.PodGroup, v1.EventTypeNormal, string(scheduling.PodGroupUnschedulableType), "queue resource quota insufficient")
return util.Reject
})
// 任务分配/回收时:实时更新队列的allocated和share值,触发调度策略的动态调整。
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
job := ssn.Jobs[event.Task.Job]
attr := pp.queueOpts[job.Queue]
attr.allocated.Add(event.Task.Resreq)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
pp.updateShare(attr)
klog.V(4).Infof("Proportion AllocateFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
DeallocateFunc: func(event *framework.Event) {
job := ssn.Jobs[event.Task.Job]
attr := pp.queueOpts[job.Queue]
attr.allocated.Sub(event.Task.Resreq)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
pp.updateShare(attr)
klog.V(4).Infof("Proportion EvictFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
})
}
