

五、Training a ML Model
训练通常被认为是机器学习工作中的“核心”部分。我们的目标是创建一个能够准确预测未见结果的函数(即“模型”)。直观上,模型训练与人类学习新技能的过程非常相似——我们观察、练习、纠正错误,并逐步改进。在机器学习中,我们从一个初始模型开始,这个模型可能表现不佳。然后,我们通过一系列训练步骤来优化模型,将训练数据输入模型。在每个训练步骤中,我们将模型生成的预测结果与真实结果进行比较,评估模型的性能。接着,我们调整模型的参数(例如,改变每个特征的权重),以提高模型的准确性。一个好的模型能够在不过度拟合特定输入的情况下做出准确的预测。
1、使用TensorFlow构建推荐系统
让我们首先来看一下TensorFlow——这是一个由Google开发的开源机器学习框架。它目前是机器学习应用中最流行的库之一,特别是在实现深度学习方面。TensorFlow对各种硬件(包括CPU、GPU和TPU)上的计算任务提供了强大的支持。我们选择TensorFlow作为本教程的工具,是因为它的高级API用户友好,并且抽象了许多复杂的细节。
什么是deep learning
近年来,深度学习——一类利用人工神经网络从输入数据中逐步提取更高层次特征的算法变得越来越流行。深度学习能够利用神经网络中的隐藏层来学习输入的高度抽象模型。
深度学习算法可以在许多日常应用中找到,如图像识别和自然语言处理。神经网络的多层隐藏层使这些算法能够从数据中发现越来越抽象的细节。例如,在图像分类神经网络中,初始层可能只能发现物体的边缘,而更深层的网络可以学习更复杂的特征并对图像中的物体进行分类。
让我们通过一个简单的教程来熟悉TensorFlow。在第一章中,我们介绍了我们的案例研究,其中之一是为客户推荐产品的系统。在本章中,我们将使用TensorFlow实现该系统。具体来说,我们将做两件事:
1. 使用TensorFlow训练一个产品推荐模型。
2. 使用Kubeflow封装训练代码并将其部署到生产集群中。
TensorFlow的高级Keras API使得实现我们的模型相对容易。事实上,模型的大部分可以用不到50行Python代码实现。
Keras 是 TensorFlow 的高级深度学习模型 API,具有用户友好的界面和高度可扩展性。作为额外优势,Keras 提供了许多现成的常见神经网络实现,因此您可以立即启动并运行模型。
让我们首先为推荐系统选择一个模型。我们从简单的假设开始——如果两个人(Alice 和 Bob)对一组产品的看法相似,那么他们对其他产品的看法也更可能相似。换句话说,Alice 与 Bob 的偏好更可能一致,而不是与随机选择的第三个人。因此,我们可以仅使用用户的购买历史来构建推荐模型。这就是协同过滤的理念——我们从许多用户那里收集偏好信息(因此称为“协同”),并使用这些数据进行选择性预测(因此称为“过滤”)。
为了构建这个推荐模型,我们需要以下几项:
Users’ purchasing history:我们将使用此GitHub仓库中的示例输入数据。
Data storage:为确保我们的模型能够在不同平台上运行,我们将使用MinIO作为存储系统。
Training model:我们使用的实现基于GitHub上的一个Keras模型。
我们将首先使用Kubeflow的notebook服务器对该模型进行实验,然后通过Kubeflow的TFJob API将训练任务部署到我们的集群中。
2、Getting Started
让我们从下载所需的准备工作开始。你可以从本书的GitHub仓库下载notebook。要运行notebook,你需要一个包含MinIO服务的Kubeflow集群。请参考第33页的“支持组件”来配置MinIO。确保MinIO客户端(“mc”)也已安装。我们还需要准备数据以便进行训练:你可以从这个GitHub网站下载用户购买历史数据。然后,你可以使用MinIO客户端创建存储对象,如示例7-1所示。


kubectl port-forward -n kubeflow svc/minio-service 9000:9000 &
mc config host add minio http://localhost:9000 minio minio123
mc mb minio/data
mc cp go/src/github.com/medium/items-recommender/data/recommend_1.csv minio/data/recommender/users.csv
mc cp go/src/github.com/medium/items-recommender/data/trx_data.csv minio/data/recommender/transactions.csv现在让我们开始创建一个新的notebook。您可以通过导航到Kubeflow仪表板中的“Notebook Servers”面板,然后点击“New Server”并按照指示操作来完成此操作。
在本示例中,我们使用tensorFlow-1.15.2notebook-cpu:1.0镜像。当Notebook服务器启动后,点击右上角的“Upload”按钮并上传Recommender_Kubeflow.ipynb文件。点击该文件以启动一个新会话。
代码的前几部分涉及导入库并从MinIO读取训练数据。然后我们对输入数据进行归一化,以便开始训练。
现在我们的notebook已设置好,数据也已准备就绪,我们可以创建一个TensorFlow会话,如示例7-2.2所示。


这是我们模型类的基础。它包括一个构造函数,其中包含一些代码,用于使用Keras API实例化协同过滤模型,以及一个“rate”函数,我们可以使用该函数通过我们的模型进行预测——即客户对特定产品的评分。
我们可以创建一个模型的实例,如示例7-4所示。

现在我们准备开始训练模型。我们可以通过设置一些超参数来实现,如示例7-5所示。

这些是控制训练过程的超参数。它们通常在训练开始之前设置,与模型参数不同,模型参数是从训练过程中学习得到的。为超参数设置正确的值可以显著影响模型的效果。现在,我们先为它们设置一些默认值。在第10章中,我们将探讨如何使用Kubeflow来调优超参数。
我们现在准备运行训练代码。请参见示例7-6。

训练完成后,您应该会看到类似于示例7-7中的结果。

恭喜:您已成功在Jupyter Notebook中训练了一个TensorFlow模型。但我们还没有完全结束——为了以后能够使用我们的模型,我们应该先将其导出。您可以通过使用MinIO Client设置导出目标来完成此操作,如示例7-8所示。

3、部署TensorFlow Training Job
到目前为止,我们已经使用Jupyter Notebook进行了一些TensorFlow训练,这是一种非常棒的快速原型设计和实验方法。但很快我们可能会发现原型不够完善——也许我们需要使用更多数据来优化模型,或者需要使用专用硬件进行训练。有时,我们甚至需要持续运行训练任务,因为我们的模型在不断进化。
最重要的是,我们的模型必须能够部署到生产环境中,以便处理实际的客户请求。
为了满足这些需求,我们的训练代码必须能够轻松打包并部署到各种不同的环境中。实现这一目标的方法之一是使用TFJob——一种Kubernetes自定义资源(通过Kubernetes operator tf-operator实现),可用于在Kubernetes上运行TensorFlow训练任务。
我们将首先将推荐系统部署为单容器的TFJob。由于我们已经有了一个Python notebook,将其导出为Python文件非常简单——只需选择“文件”,然后选择“下载为”并选择“Python”。这将把notebook保存为可执行的Python文件。下一步是将训练代码打包到容器中。这可以通过Dockerfile完成,如示例7-10所示。

接下来,我们需要构建此容器及其所需的库,并将容器镜像推送到仓库:

完成后,我们即可为TFJob创建规范,如示例7-11所示。

apiVersion字段指定您使用的TFJob自定义资源的版本。相应的版本(在本例中为v1)需要安装在您的Kubeflow集群中。
kind字段标识了自定义资源的类型——在本例中为TFJob。
元数据字段是所有Kubernetes对象共有的,用于在集群中唯一标识对象——您可以在此添加诸如名称、命名空间和标签等字段。
架构中最重要的部分是`tfReplicaSpecs`。这是对TensorFlow训练集群及其期望状态的实际描述。在本例中,我们只有一个工作副本。在接下来的部分中,我们将进一步探讨这个字段。
这个TFJob是不是就是对pod进行了一个包装?
现在将TFJob部署到您的集群中,如示例7-12所示。

您可以使用示例7-13中的命令监控TFJob的状态。

这应该显示类似示例 7-14 的内容。
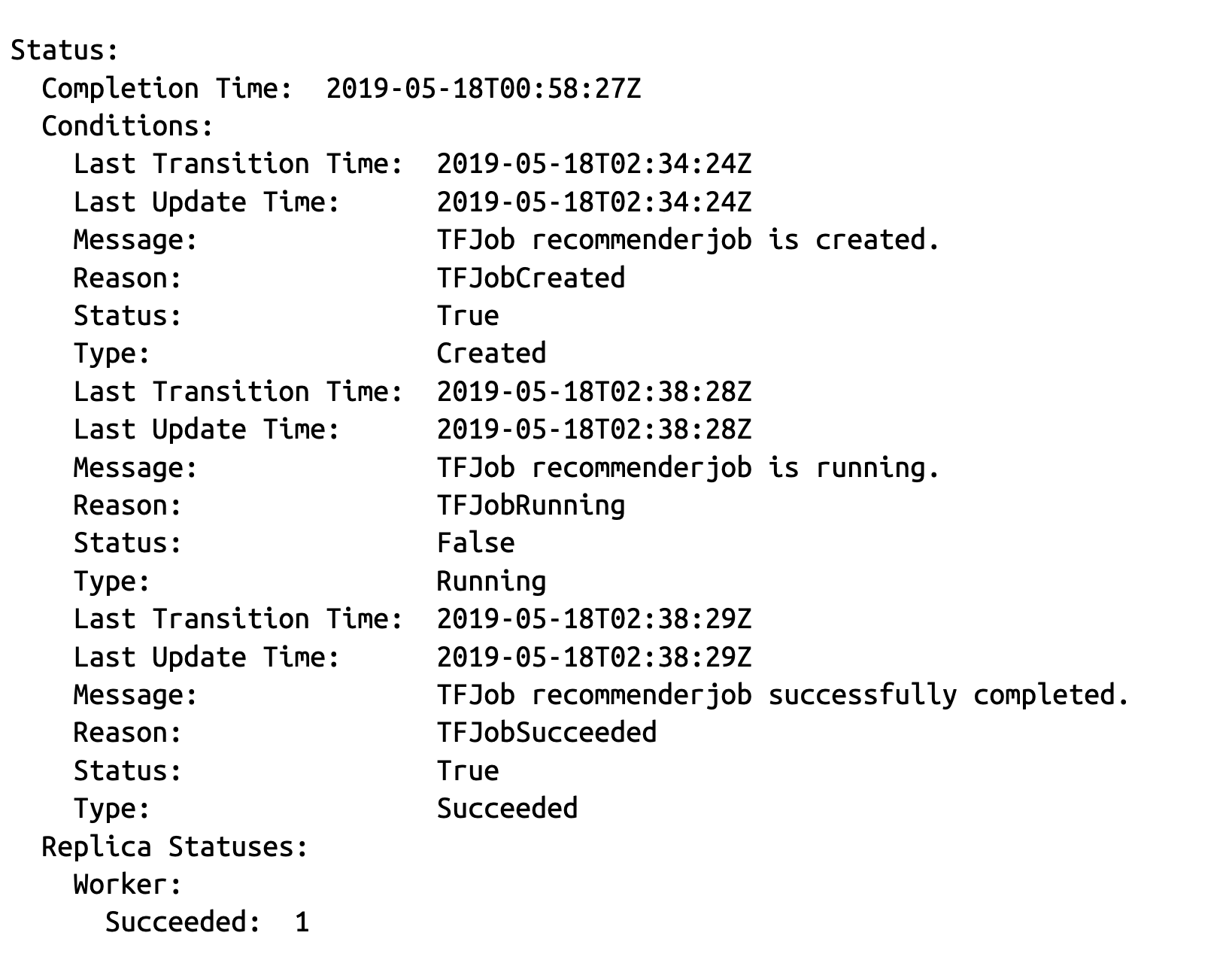
请注意,状态字段包含一系列作业条件,这些条件表示作业何时进入每个状态。这对于调试非常有用——如果作业失败,失败的原因将显示在这里。
到目前为止,我们已经训练了一个相当简单直接的模型,使用了适量的训练样本。在实际情况中,学习更复杂的模型可能需要显著更多的训练样本或模型参数。这些模型可能过大且计算复杂,无法由一台机器处理。这就是分布式训练的用武之地。
4、分布式训练
截至目前,我们已经使用Kubeflow部署了一个单工作节点的TensorFlow任务。之所以称为“单工作节点”,是因为从数据托管到实际执行训练步骤的所有操作都在一台机器上完成。然而,随着模型变得越来越复杂,单台机器通常不足以满足需求——我们可能需要将模型或训练样本分布在多台联网的机器上。TensorFlow支持分布式训练模式,在这种模式下,训练会在多个工作节点上并行执行。
分布式训练通常有两种形式:数据并行和模型并行。在数据并行中,训练数据被分割成多个块,相同的训练代码在每个块上运行。在每个训练步骤结束时,每个工作节点会将其更新信息传递给所有其他节点。模型并行则相反——所有工作节点使用相同的训练数据,但模型本身被分割。在每个步骤结束时,每个工作节点负责同步模型的共享部分。
TensorFlow 中的分布式策略
TensorFlow 支持多种不同的分布式训练策略,包括:
镜像策略(Mirrored Strategy)
这是一种同步策略,意味着训练步骤和梯度在所有副本之间同步。模型中的所有变量副本会在所有工作设备的每个设备上复制。
TPU 策略(TPU Strategy)
与镜像策略类似,但允许在 Google 的 TPU 上进行训练。
多工作器镜像策略(MultiWorker Mirrored Strategy)
同样类似于镜像策略,但使用 CollectiveOps 多工作器全归约(all-reduce)来保持变量同步。
中央存储策略(Central Storage Strategy)
该策略不将所有变量复制到所有工作器上,而是将变量存储在中央 CPU 上,同时在多个工作器之间复制计算任务。
参数服务器策略(Parameter Server Strategy)
节点被分类为工作器或参数服务器。每个模型参数存储在一个参数服务器上,而计算任务在工作器之间复制。
TFJob 接口支持多工作节点的分布式训练。从概念上讲,TFJob 是与训练任务相关的所有资源(包括 Pod 和服务)的逻辑分组。在 Kubeflow 中,每个复制的 worker 或参数服务器都调度在各自的单容器 Pod 上。为了使副本之间能够相互同步,每个副本都需要通过一个端点(即 Kubernetes 内部服务)暴露自身。将这些资源逻辑上分组到一个父资源(即 TFJob)下,使得这些资源能够被共同调度并一起进行垃圾回收。
在本节中,我们将部署一个简单的MNIST示例,并进行分布式训练。TensorFlow训练代码已在此GitHub仓库中提供。
让我们看一下示例7-15中用于分布式TensorFlow作业的YAML文件。

请注意,tfReplicaSpecs 字段现在包含几种不同的副本类型。在一个典型的 TensorFlow 训练集群中,有几种可能的副本类型:
Chief:负责协调计算任务、发出事件以及对模型进行检查点保存。
Parameter servers:为模型参数提供分布式数据存储。
Worker:这是实际进行计算和训练的地方。如果没有明确指定 chief 节点(如前面的示例所示),其中一个 worker 将充当 chief 节点。
Evaluator:评估器可用于在模型训练过程中计算评估指标。
请注意,副本规范包含多个描述其期望状态的属性:
replicas:应为该副本类型生成的副本数量。
template:描述为每个副本创建的 Pod 的 PodTemplateSpec。
restartPolicy:决定 Pod 退出时是否会被重启。允许的值如下:
Always:表示 Pod 将始终被重启。此策略适用于参数服务器,因为它们永远不会退出,并且在发生故障时应始终重启。
OnFailure:表示如果 Pod 因故障退出,则将被重启。非零退出代码表示故障,退出代码为 0 表示成功且 Pod 不会被重启。此策略适用于 chief 和 workers。
ExitCode:表示重启行为取决于 TensorFlow 容器的退出代码,具体如下:
Never:表示终止的 Pod 永远不会被重启。此策略应极少使用,因为 Kubernetes 可能因多种原因(例如节点不健康)终止 Pod,这将阻止作业恢复。
一旦您编写好TFJob规范,将其部署到您的Kubeflow集群中:
kubectl apply -f dist-mnist.yaml监控作业状态类似于单容器作业:
kubectl describe tfjob mnist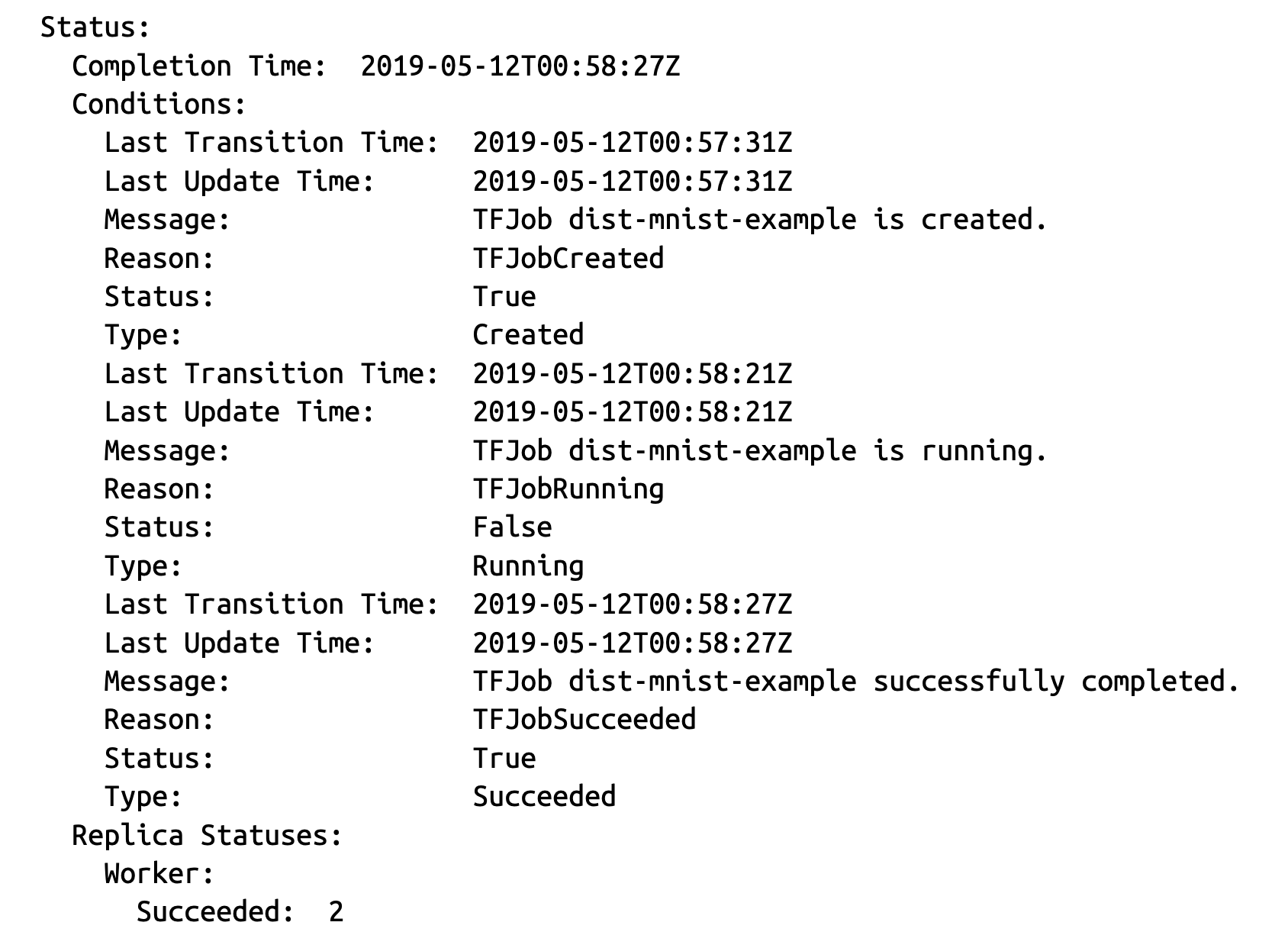
请注意,Replica Statuses 字段显示了每种副本类型的状态细分。当所有 worker 完成时,TFJob 即成功完成。如果任何 worker 失败,则 TFJob 的状态也会显示为失败。
5、使用其他框架进行分布式训练
Kubeflow 被设计为一个多框架的机器学习平台。这意味着分布式训练的架构可以轻松扩展到其他框架。截至本文撰写时,已经有许多操作符被编写,以提供对其他框架的一流支持,包括 PyTorch 和 Caffe2。示例 7-18 展示了一个 PyTorch 训练任务的规范。


